曾经一个研发大佬说过这样一句话,大概意思是只要你把需求整理出来,研发就能实现。我想对他说,能否帮忙生成一个随机数?
我们接触到的计算机生成的随机数其实都是都称为“伪随机数”。计算机本质上是确定性的,因此无法生成真正的随机数。还有一种可以算出真随机的生成方式是采用硬件获取外部的噪音生成随机数。通常,我们将计算机生成的随机数分为两类:伪随机数和真随机数。
伪随机数(Pseudo-Random Numbers)
- 伪随机数是通过算法生成的,这些算法(如线性同余生成器、梅森旋转器等)基于一个初始值(种子)来生成数字序列。这个序列在统计上看起来像是随机的,但实际上是完全确定的,因为如果你知道算法和种子,就能预测出所有的数字。
- 计算机通常生成的是伪随机数,因为这些数可以快速且一致地生成,并且对于大多数应用来说足够“随机”。
真随机数(True Random Numbers)
- 真随机数的生成依赖于物理过程,这些过程本质上是不可预测的,如放射性衰变、热噪声、光噪声等。
- 真随机数生成器(TRNGs)通常需要专门的硬件来捕捉和转化这些物理过程的随机性。因此,它们不像伪随机数生成器那样普遍。
对于大多数应用来说,伪随机数足够好,因为它们能提供良好的统计特性,且易于控制和重现。但在一些特定领域,如密码学和高级安全应用,可能需要真随机数来确保最高级别的不可预测性和安全性。
存在真随机数?
如果物理定律是确定的,那么理论上,依赖于这些物理过程的随机数生成也应该是确定的。然而,这个问题涉及到物理学中的一个核心概念:经典物理学(如牛顿力学)与量子力学之间的区别。
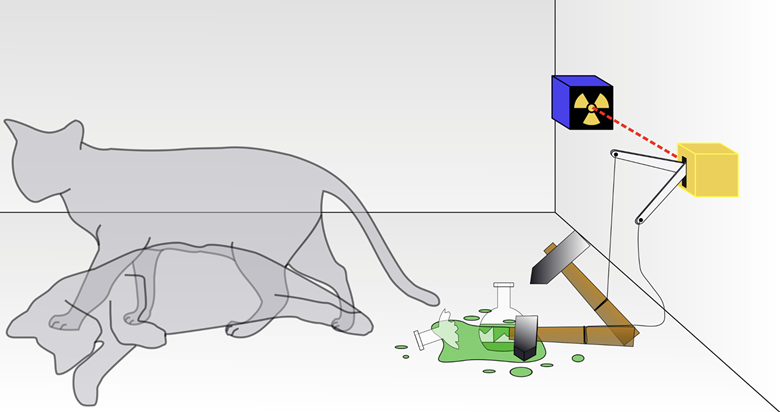
经典物理学的确定性。
在经典物理学的框架下,物理过程被认为是完全确定的。如果我们知道了所有相关的初始条件和物理定律,理论上我们可以准确预测任何物理系统的未来状态。但在实际应用中,由于初始条件的复杂性和测量的不精确,预测具体事件(如掷骰子的结果)仍然具有不确定性。
量子力学的不确定性
- 在量子力学中,即使是在完全已知的初始条件下,某些事件的结果也具有根本性的不确定性。例如,量子叠加和量子纠缠等现象意味着即使在理论上也无法准确预测个别量子事件的结果。
- 基于量子过程的随机数生成器(如使用量子噪声或量子纠缠的设备)利用这种根本性的不确定性来产生真随机数。
因此,当我们说一个基于物理过程的随机数生成器是“确定的”时,我们实际上是指在经典物理学的范畴内。但在量子力学层面,即使物理定律是确定的,某些物理过程(特别是量子过程)本身就是不确定的,从而能够产生真正的随机性。
不可预知≠随机
上面讲到了量子力学的不确定,但这个不确认是由于真的不确定,还是由于测量水平或认知水平导致的无法根据已知条件推断结果产生的不确定性?举个例子:几百年前我们无法准确的预知日食,在那个年代,日食被认为不确定。但随着物理学的不断推进,到现在日食是可以被预知的,也就是日食是确定的。
物理世界的确定性与自由意志
物理世界的确定性
在物理学中,尤其是在经典物理学领域,世界被视为一个确定的、机械的系统。在这个框架下,如果知道了所有初始条件和自然定律,理论上可以预测未来的状态。然而,量子力学引入了不确定性的概念,即在微观层面,事件的结果具有根本性的随机性。然而,即使在量子层面存在不确定性,它是否影响宏观世界(如人类行为)仍然是一个开放的问题。
自由意志的存在
- 自由意志是指个体在没有外部强制的情况下做出选择的能力。在哲学和神经科学中,关于自由意志的本质存在着广泛的讨论。一种观点认为,如果我们的行为完全由大脑中的神经活动决定,而这些神经活动又受到遗传和环境的影响,那么自由意志可能只是一种幻觉。
- 另一方面,有理论认为,尽管我们的决策受到多种因素的影响,但人类仍然有能力在一定程度上自主地做出选择。这个观点认为,即使在确定的物理环境中,个体也能展现出一定程度的自由意志。
这个问题没有简单的答案。一方面,物理定律可能在很大程度上决定了我们所处的世界和我们的行为模式;另一方面,关于自由意志的存在和本质仍是哲学和科学研究的重要议题。不同的学科和理论对这个问题有不同的看法,而这个讨论也仍在进行中。
ChatGPT与人类
ChatGPT:
- 每次回答都是根据算法、训练数据和您提出的具体问题确定的。
- 通过分析大量文本数据来训练的,这些数据包括书籍、文章、网站内容等。反映了这些数据中的信息和模式。
- 使用机器学习算法来理解和生成语言。这些算法根据输入的问题分析可能的回答,并选择最合适的回答。
- 对问题的理解和回答取决于用户的具体提问。不同的提问方式可能会导致不同的回答。
你能判断ChatGPT是否有自由意识吗?原理上ChatGPT不能自主地做出决策或产生思想,只能根据编程和训练数据来生成回答。
人类:
- 人们的过往经历、教育背景和文化环境等都构成了个人的“历史数据”,影响着个人的行为模式、决策习惯和价值观念。这类似于语言模型依赖于训练数据来形成回答的基础。
- 遗传基因在某种程度上预设了个体的身体特征、潜在的健康风险和可能的行为倾向。这类似于一个程序或模型的基础架构或规则设定。
- 人类大脑处理信息和做出决策的方式可以类比为“算法”。这些“算法”包括逻辑推理、情绪反应、直觉判断等,是基于大脑的生物化学过程和神经网络结构的。
- 个体所处的环境、遇到的具体情境和即时的刺激相当于“用户输入”,这些因素直接影响着个体的行为和决策。
人类与人工智能是否存在本质区别?
人类有情感机器没有?
研究表明,当用户以更加礼貌的方式与ChatGPT进行对话时,可能会获得更好的回答。我们可以从原理层面来回答为什么会出现这样的现象。
- 作为语言模型,在训练过程中所接触的大量文本数据。这些数据中,礼貌、专业和正式的语言使用往往与高质量、详尽、准确的信息相关联。因此,当用户的询问方式类似于这些高质量的文本时,模型更有可能生成类似质量的回答。
- 礼貌的对话往往伴随着更清晰和具体的问题表述。用户在礼貌地提问时,往往会更加注意表达的清晰度和完整性,这使得模型更容易理解问题的真正意图,并据此提供准确的回答。
- 礼貌的表达通常避免了侮辱性语言、模糊不清的指代和过于简短的提问,这些因素可能导致模型理解错误或无法提供有效的答案。通过礼貌和明确的沟通,可以减少这些误解和歧义。
- ChatGPT在回应时也倾向于模仿用户的语言风格。如果用户使用礼貌和专业的语言,我也会以类似的方式回答。这种相互作用可能导致更高质量的对话。
以上行为反馈模式是否和人类一致?我们是否存在自由意识这本身就是一个深刻的哲学问题。
三体世界中的偶尔与必然
在刘慈欣的小说《三体》中描述了一个三体文明,该文明的主要工作是让“随机”的三体问题产生确定性。”三体问题”指的是一个在天体力学中的问题,描述了在引力作用下,三个质点之间相互运动的复杂性。

具体来说,这个问题考虑的是三个质点之间只受引力相互作用,并且初始时它们的位置和速度都是已知的。然而,尽管这个问题看似简单,却在一般情况下无法精确求解。
- 非线性性:三体问题的方程是非线性的,这意味着质点之间的相互作用不是简单的线性关系。非线性方程组的解通常难以用封闭形式表示。
- 混沌性:三体问题具有混沌性质,即微小的初值差异可能会导致长期的、不可预测的运动。这使得随着时间的推移,系统的行为变得极其复杂,难以准确预测。
- 无法找到通解:比较简单的两体问题有解析解,但三体问题的解析解在一般情况下是不存在的。这是因为三体问题涉及到更多的自由度和复杂的相互作用,难以找到通用的数学表达式。
尽管一般的三体问题难以解决,但在一些特殊情况下,比如限制性三体问题(其中一个质点质量很小)可以找到一些近似解。这些特殊情况通常对实际问题的简化程度要求较高。
从三体的故事中我们可以发现:复杂度可以决定是否可预知性,但是不代表随机性。
随机数的性质
随机数的性质大概可以分成3种,分别是随机性、不可预测性和不可重现性。它们的定义如下:
- 随机性:不存在统计学上的偏差,是完全杂乱无章的数列。
- 不可预测性:无法从过去的已经生成的数列中推测出下一个数。
- 不可重现性:对于过去出现的数列,以后不会再次出现相同的数列。
这三种特性可以看作是对随机数的约束条件。其中,随机性的约束最弱,不可重现性的约束最强。具备不可重现性,则一定具备不可预测性和随机性。具备不可预测性,则一定具备随机性。简言之,后者是前者的充分非必要条件。

根据约束的强弱,我们把满足上述三种特性的随机数依次称为“弱伪随机数”,“强伪随机数”,“真随机数”。如下表格。需要注意的是,应用在安全系统中的随机数至少具备不可预测性。就是说,弱伪随机数是不能用在安全系统中的。
| 名称\特性 | 随机性 | 不可预测性 | 不可重现性 | 备注 |
| 弱伪随机数 | ☑️ | ✖️ | ✖️ | 不可用于安全系统 |
| 强伪随机数 | ☑️ | ☑️ | ✖️ | 可用于安全系统 |
| 真随机数 | ☑️ | ☑️ | ☑️ | 可用于安全系统 |
计算机随机数生成原理
伪随机数生成器(PRNGs)的发展经历了多个重要的版本和改进,这些版本反映了计算机科学和数学理论的进步。下面是一些主要的发展阶段:
- 线性同余法 (Linear Congruential Generator, LCG)
- 早期伪随机数生成算法之一。
- 算法使用线性同余的形式,通过乘法和加法操作生成下一个随机数。
- 简单但容易受到周期性和统计特性的限制。
- 梅森旋转算法 (Mersenne Twister):
- 1997年由松本眞等人提出。
- 使用一个大的梅森素数作为周期,提高了周期性和统计特性。
- 在许多应用中广泛使用,被认为是高质量的伪随机数生成器。
- Park-Miller-Carta伪随机数生成器:
- 1988年由Park和Miller提出。
- 使用2^31-1作为素数周期,成为C语言标准库rand函数的实现基础。
- XORshift算法
- 2003年由George Marsaglia提出。
- 通过位运算的异或操作实现快速且高质量的伪随机数生成。
- 相对于一些传统方法,它的周期性较好。
- PCG (Permuted Congruential Generator)
- 2014年由Melissa O’Neill提出。
- 结合了线性同余法和置换操作,提供了更好的统计特性。
- 具有良好的性能和周期性,广泛用于游戏和模拟等领域。
线性同余法 (Linear Congruential Generator, LCG)
线性同余生成器是一种简单的伪随机数生成算法。其基本原理是通过线性方程来生成一系列的数字,这些数字表面上看起来是随机的,但实际上是完全确定的。这种方法广泛用于计算机程序中的伪随机数生成。
线性同余法是一种简单的伪随机数生成方法,其基本思想是通过一个递推式,每次生成下一个伪随机数。具体来说:
- 初始化:选择一个初始值(种子),通常用于设置随机数生成的起点。
- 递推式:使用线性同余的递推式,将当前随机数转换为下一个随机数。典型的递推式形式是:$X_{n+1} = (a * X_{n} + c) % m$。其中,$X_n$是当前随机数,a是乘法因子,c是增量,m是模数(确定生成的范围)。
- 重复:不断使用递推式生成新的随机数。
重要的是选择适当的参数,以避免出现很短的周期、重复性或其他统计不足的问题。常见的选择包括使用大素数作m,选择适当的a和c,以及合理的初始种子。
在早期的C语言编程中,一个基本的线性同余生成器(LCG)可以用以下方式实现:
#include <stdio.h>
// 定义线性同余生成器的参数
unsigned long a = 1103515245;
unsigned long c = 12345;
unsigned long m = 2147483648; // 2^31
unsigned long seed = 0; // 种子
// 线性同余生成器函数
unsigned long lcg() {
seed = (a * seed + c) % m;
return seed;
}
int main() {
// 设置种子值
seed = 123; // 可以设置任意初始种子值
// 生成随机数
for (int i = 0; i < 10; i++) {
printf("%lu\n", lcg());
}
return 0;
}
a、c和m是线性同余生成器的参数,这些值的选择会影响随机数序列的质量。seed是初始的种子值,不同的种子值会产生不同的随机数序列。lcg()函数实现了线性同余生成器的主要算法。在main()函数中,我们通过调用lcg()函数来生成一系列的伪随机数。
在提供的代码中,seed的初始值为123,这个值会被lcg函数使用。在lcg函数中,每次调用时,都会根据当前的seed值计算下一个随机数,并更新seed的值。这意味着,lcg函数的输出(即生成的伪随机数)依赖于seed的当前值。
在选择线性同余生成器(LCG)的参数a, c, 和m 时,目的是为了确保生成的伪随机数序列具有良好的统计特性,比如较长的周期和较好的均匀性。选取这些参数的原则包括:
- 模数m: 通常选择为2的幂,例如$2^{31}$或$2^{32}$,因为这可以简化取模运算,使其更适合于计算机处理。更大的m值通常可以产生更长的周期。
- 乘数a和增量c: 这些值需要仔细选择,以确保随机数生成器有着良好的统计特性。存在一些经验法则和理论准则用于选择a和c。例如,Knuth提出的一些选择准则是:
- a-1可以被m的所有素因子整除。
- 如果m是4的倍数,那么a-1也应该是4的倍数。
- c和m应该是互质的(即最大公约数为1)。
a-1可以被m的所有素因子整除
要理解”(a-1)可以被(m)的所有素因子整除”这一准则,我们需要先了解素因子和线性同余生成器(LCG)周期性的概念。
- 素因子:一个数的素因子是指能整除这个数的素数。例如,数12的素因子包括2和3,因为12可以被2和3整除。
- 线性同余生成器的周期:线性同余生成器生成的伪随机数序列是周期性的,这意味着序列最终会重复。理想情况下,我们希望这个周期尽可能长,以便生成器能产生更多的不重复的随机数。
现在来看这个准则:(a-1)可以被(m)的所有素因子整除”。这个准则是为了确保LCG能达到最大可能的周期,也就是接近或等于m。这是因为:
- LCG的周期最多只能达到 m,这是因为它在每一步都是对 m 取模,因此不可能产生超过 m$ 个不同的值。
- 当 (a-1) 能被 (m) 的所有素因子整除时,它有助于确保每个可能的种子值(从 0 到 m-1)都能在序列中出现,从而使得周期最大化。
简而言之,这个准则有助于确保 LCG 能生成具有较长周期的随机数序列,从而提高了其作为随机数生成器的有效性。但需要注意的是,即使遵守了这个准则,LCG 生成的仍然是伪随机数序列,其随机性和真实随机性相比仍有限。
如果 m 是 4 的倍数,那么 a-1 也应该是 4 的倍数
要理解为什么当模数 m 是 4 的倍数时,乘数 a 减 1 也应该是 4 的倍数,我们需要考虑线性同余生成器(LCG)的周期性和其在特定条件下的行为。
首先,回顾一下线性同余生成器的基本形式:
$$X_{n+1} = (aX_n + c) \mod m$$
这里,$X_{n+1}$ 是序列中的下一个数 $X_n$ 是当前的数,而 a, c, 和 m 是生成器的参数。
LCG 的目标是产生一个长周期的伪随机数序列。为了实现这一点,需要确保该序列能够探索其全部可能的状态空间,即从 0 到 m-1 的所有整数。如果 m 是 4 的倍数,那么要实现这一点,就需要 a-1 也是 4 的倍数。这是因为:
- 偶数与奇数的混合:当 m 是 4 的倍数时,它能被 2 整除两次,这意味着它包含了较多的偶数。为了确保生成器能够均匀地覆盖这些偶数和奇数,需要 a 的选择能够适应这种结构。特别地,当 a-1 是 4 的倍数时,这有助于保证序列中偶数和奇数的均匀出现。
- 周期的最大化:与前面的规则一样,这个规则也是为了最大化 LCG 的周期。当 a-1 是 4 的倍数时,它能更好地与 m 的结构相匹配(特别是当 m 是 4 的倍数时),从而帮助序列达到更大的周期。
综上,这个规则帮助确保当模数 m 是 4 的倍数时,LCG 能够更有效地遍历其可能的状态空间,从而产生一个具有较长周期的伪随机数序列。这一点对于确保生成的随机数质量至关重要,尤其是在需要伪随机数具有良好统计特性的应用中。
梅森旋转算法(Mersenne Twister)
梅森旋转算法(Mersenne Twister)是一种广泛使用的伪随机数生成器算法。它由松本真和西村拓士在 1997 年开发,主要特点是具有极长的周期和较高的均匀度。以下是梅森旋转算法的一些关键特征:
- 极长的周期:梅森旋转算法的一个最著名特点是其极长的周期。最常用的版本 MT19937 的周期为 $2^{19937}-1$,这是一个梅森素数(Mersenne prime),因此得名。这个周期远远超过了大多数实际应用的需要。
- 高维度均匀分布:梅森旋转算法能产生高质量的伪随机数,这些随机数在高达 623 维度上均匀分布。这意味着在多维空间中,生成的随机点分布非常均匀。
- 实现方式:算法基于一个巨大的位移寄存器(通常为 19937 位),使用特定的线性递归公式更新。在每次生成随机数时,它会改变寄存器的状态,从而产生新的随机数。
- 效率和可移植性:梅森旋转算法在现代计算机上运行效率高,且容易实现,保证了良好的可移植性。它在多种编程语言和系统中被广泛采用。
- 用途:由于其优良的统计性质和长周期,梅森旋转算法被广泛用于各种需要随机数的应用中,如模拟、计算机图形学和游戏开发。但需要注意,由于它不是加密安全的随机数生成器,不适合用于加密或安全相关的应用。
尽管梅森旋转算法有很多优点,但它也有一些缺陷,比如状态空间较大,且如果初始状态(种子)不当,可能需要较长的时间来”热身”(达到理想的随机分布状态)。此外,由于其算法结构,一旦部分输出被破译,剩余部分也容易被预测。因此,在需要更高安全性的场合,应该使用专为安全性设计的伪随机数生成器。
不同编程语言下的随机算法
目前主流编程语言中自带的伪随机数算法各有不同,以下是一些常见编程语言及其伪随机数算法:
- C/C++:C/C++ 标准库中的 rand() 函数通常实现了线性同余生成器(Linear Congruential Generator, LCG)。C++11 引入了更多选项,比如梅森旋转算法(Mersenne Twister)。
- Python:Python 的 random 模块默认使用梅森旋转算法(Mersenne Twister),这是一种常用的高质量伪随机数生成器。
- Java:Java 在 util.Random 类中默认使用的是线性同余生成器。但是,Java 还提供了其他选择,如 java.security.SecureRandom,这是一个更安全的伪随机数生成器,常用于加密应用。
- JavaScript:JavaScript 中的 random() 通常是浏览器或 JavaScript 引擎实现的,具体算法可能会有所不同。但多数情况下,它们使用的是伪随机数生成算法,如线性同余生成器或其他类似的算法。
- Ruby:Ruby 的伪随机数生成通常使用梅森旋转算法。
- PHP:PHP 在 rand() 和 mt_rand() 函数中使用了不同的算法。mt_rand() 使用了梅森旋转算法,而 rand() 的实现取决于平台。PHP 7.1.0 起,rand() 和 mt_rand() 使用相同的随机数生成器。
- Go:Go 语言在 `math/rand` 包中提供了伪随机数生成,其默认使用的是一种线性同余生成器。
可以看到线性同余生成器并没有被时代淘汰。包括年龄最小的 Go 语言也在使用。Go 语言标准库中 math/rand 包的 Intn 函数的实现逻辑是基于线性同余生成器(Linear Congruential Generator,LCG)的。
以下是简化版本的 Intn 实现逻辑:
package rand
var (
// 种子,初始值设为 1
seed int64 = 1
)
// Intn 返回 [0,n) 范围内的伪随机整数。
func Intn(n int) int {
if n <= 0 {
panic("invalid argument to Intn")
}
// LCG 参数
const (
a int64 = 1103515245
c int64 = 12345
m int64 = 2147483648
)
// 通过线性同余生成器计算下一个伪随机数
seed = (a * seed + c) % m
// 将伪随机数映射到 [0,n) 范围
return int(seed % int64(n))
}
随机数的周期性
伪随机数是由确定性算法生成的数列,它们在某种程度上模拟了随机数的性质,但由于算法的确定性,这些数列实际上是可预测的。伪随机数生成器(PRNG)通常基于一个初始值,称为种子(seed),通过数学运算产生数列。
伪随机数的周期性是指 PRNG 在生成数列时最终会重复相同的数列片段。这个重复的数列片段称为周期(period),而整段周期之前的非重复序列部分称为不重复长度。周期性是 PRNG 设计中的一个重要考量因素,因为它决定了生成器的使用寿命和产出数列的随机性质。
周期性的特点包括:
- 周期长度:一个理想的 PRNG 会有非常长的周期长度,这意味着在重复之前能够生成大量的伪随机数。例如,线性同余生成器(Linear Congruential Generators, LCG)的周期最大为它的模数(modulus),但这取决于选择的参数。
- 分布均匀性:即使 PRNG 具有长周期,如果数列中的数分布不均,则不适合某些应用。一个好的 PRNG 应该在一个周期内,数的分布尽可能接近均匀。
- 初始种子:不同的初始种子会导致不同的数列,即便是同一个 PRNG。理论上,一个 PRNG 的不同种子之间的周期不应该重叠,不过实际上这很难做到。
- 算法复杂度:一些具有长周期和良好统计特性的 PRNG 可能在计算上更复杂,这可能会影响到它们。
以下 PHP 代码在 Windows 不同 PHP 版本下生成的图片:
<?php
header("Content-type: image/png");
$im = imagecreatetruecolor(512, 512)
or die("Cannot Initialize new GD image stream");
$white = imagecolorallocate($im, 255, 255, 255);
for ($y = 0; $y < 512; $y++) {
for ($x = 0; $x < 512; $x++) {
if (rand(0, 1) === 1) {
imagesetpixel($im, $x, $y, $white);
}
}
}
imagepng($im);
imagedestroy($im);
Window环境下PHP7.4.28生成的图片:

Window环境下PHP5.6.40生成的图片:

可以看到老版本PHP有明显的周期性,新版本的随机算法使用的梅森旋转算法,周期性更长,所以上面的图片无法显现出来。即如果周期过长,我们无法准确的认知到周期是否存在。
我们是否存在与周期(轮回)中?
要证明我们是否生活在一个周期极长的循环中,是一个复杂且深奥的问题,涉及到宇宙学、哲学和物理学的多个领域。目前,我们没有确凿的科学方法或证据能够完全证明或否定这个假设。
- 科学观察和证据:至今为止,科学家没有发现任何直接证据表明我们的宇宙或人类历史是周期性的,特别是在超越已知历史长度的周期上。
- 宇宙学理论:在宇宙学中,有各种理论试图解释宇宙的起源、发展和终结,如大爆炸理论、膨胀宇宙论等。这些理论基于广泛的天文观测和物理定律。尽管有些理论(如多重宇宙理论)提出了宇宙可能具有某种形式的周期性,但这些都是高度理论化的观点,并没有直接证据支持。
- 哲学和逻辑上的考虑:从哲学角度来看,证明或否定这种大尺度周期性存在的问题类似于证明或否定任何其他无法观察到的假设。如果一个现象无法被观测或测量,那么在科学上验证它是非常困难的。
- 技术和观测的局限性:目前人类的技术和观测手段有限,我们只能观测到宇宙的一部分,并且只能追溯到大约138亿年前的大爆炸。如果宇宙的周期远远超过这个时间范围,那么我们目前的技术无法探测到这样的周期。
关于我们是否生活在一个周期极长的循环中的问题,目前仍属于高度理论化且未被证实的假设。这个问题的回答可能超出了现有科学知识和观测能力的范畴。
随机数的种子
为了生成伪随机数,计算机程序通常需要一个种子值。这个种子值是由用户提供的初始值,它用于初始化随机数生成器算法。在程序运行过程中,随机数生成器会利用这个种子值来计算下一个随机数。如果种子值相同,生成的随机数序列也将完全相同。
因此,种子值的选择对于生成随机数的质量和随机性非常重要。如果种子值是预测性的,那么生成的随机数序列也可能是可预测的。相反,如果种子值是不可预知的,那么生成的随机数序列也将是不可预知的。
通常,种子值是由系统时间生成的。在某些情况下,开发人员还可以手动指定种子值来生成特定的随机数序列。
指定随机数seed
直接控制种子值以获得可预测的随机数序列,比如在机器学习中拆分训练集和验证集时,为了每次验证随机拆分都都一致,通常也会指定seed。
from sklearn.model_selection import train_test_split # 将数据集拆分为训练集和测试集 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
这里的random_state起始就是seed。如果不使用train_test_split,则可以:
import random random.seed(42) # 设置随机种子为42 indices = list(range(len(data))) random.shuffle(indices) train_indices = indices[:int(0.8*len(data))] val_indices = indices[int(0.8*len(data)):] train_data = data[train_indices] val_data = data[val_indices]
假设一个抽奖程序的开发人员想要某个人中奖,就可以采用指定随机数序列的方式。
使用系统时间作为Seed
在计算机程序中,系统时间是一种常用的种子值来生成伪随机数的方法。这是因为系统时间会不断变化,因此可以产生看似随机的种子值。然而,这种方法也存在一些问题。
- 系统时间存在精度问题,有的是秒,有的是微秒。如果程序在短时间内多次运行,这将导致生成的随机数序列是相同的。
- 如果不同的电脑在相同时刻生成随机数,则也会出现随机数相同的场景。
- 攻击者可以通过更改系统时间来影响随机数的生成。例如,攻击者可以将系统时间更改为一个较早的时间,这将导致程序使用相同的种子值来生成随机数,从而使攻击者能够预测随机数的值。
写在最后,我们如何定义我们生活的世界?“缘分”这个既能表示偶然又有表示必然的词可以定义。你能看到这篇文章也是“缘分”。


