文章内容如有错误或排版问题,请提交反馈,非常感谢!
OpenLineage简介
OpenLineage是一个开源的标准化框架,旨在为数据生态系统提供统一的数据血缘追踪和可观察性。它定义了一套开放的API和模型,用于捕获和传递数据血缘信息,帮助企业更好地理解和管理数据管道的复杂依赖关系。通过标准化的数据血缘追踪,OpenLineage支持多种数据工具和平台的集成,使得数据工程师和数据科学家能够获得更全面的数据可观察性。
核心特性
- 标准化数据血缘模型:
- OpenLineage提供了一种标准化的数据血缘模型,用于描述数据集和数据处理作业之间的关系。
- 支持捕获和传递数据操作的输入、输出和处理步骤信息。
- 开放API:
- 提供开放的API接口,用于收集和查询数据血缘信息。
- 支持通过API与其他数据工具和平台集成,实现数据血缘信息的共享和利用。
- 多工具集成:
- 支持与多种数据工具和平台的集成,如Apache Airflow、Apache Spark、dbt、Kubernetes等。
- 通过连接器和插件机制,方便在不同环境中采集数据血缘信息。
- 可扩展性和灵活性:
- 设计为可扩展的架构,支持自定义数据血缘模型和扩展。
- 用户可以根据具体需求开发自定义的连接器和插件。
- 社区驱动:
- OpenLineage是一个社区驱动的项目,拥有活跃的开发者和用户社区。
- 社区贡献和维护各种连接器和插件,支持更多的数据工具和平台。
应用场景
- 数据管道可观察性:
- 提供数据管道的全局视图,帮助数据工程师理解和管理数据流动。
- 支持数据依赖关系的分析和优化,提高数据管道的可靠性和效率。
- 数据治理和合规性:
- 提供详细的数据血缘信息,支持数据治理和合规性要求。
- 帮助识别和追踪数据的来源、去向和变更历史。
- 数据质量管理:
- 支持数据质量监控和问题诊断,帮助识别和解决数据质量问题。
- 提供数据血缘信息,支持数据质量的根因分析。
- 影响分析:
- 支持数据变更的影响分析,帮助用户理解和评估数据变更的影响。
- 提供数据血缘信息,支持数据管道的变更管理和优化。
OpenLineage的架构
OpenLineage是一个开源的元数据和数据血缘跟踪项目,旨在为数据生态系统提供一个标准化的方式来收集、存储和查询数据血缘信息。其架构设计旨在灵活、可扩展,并易于集成到现有的数据工作流中。
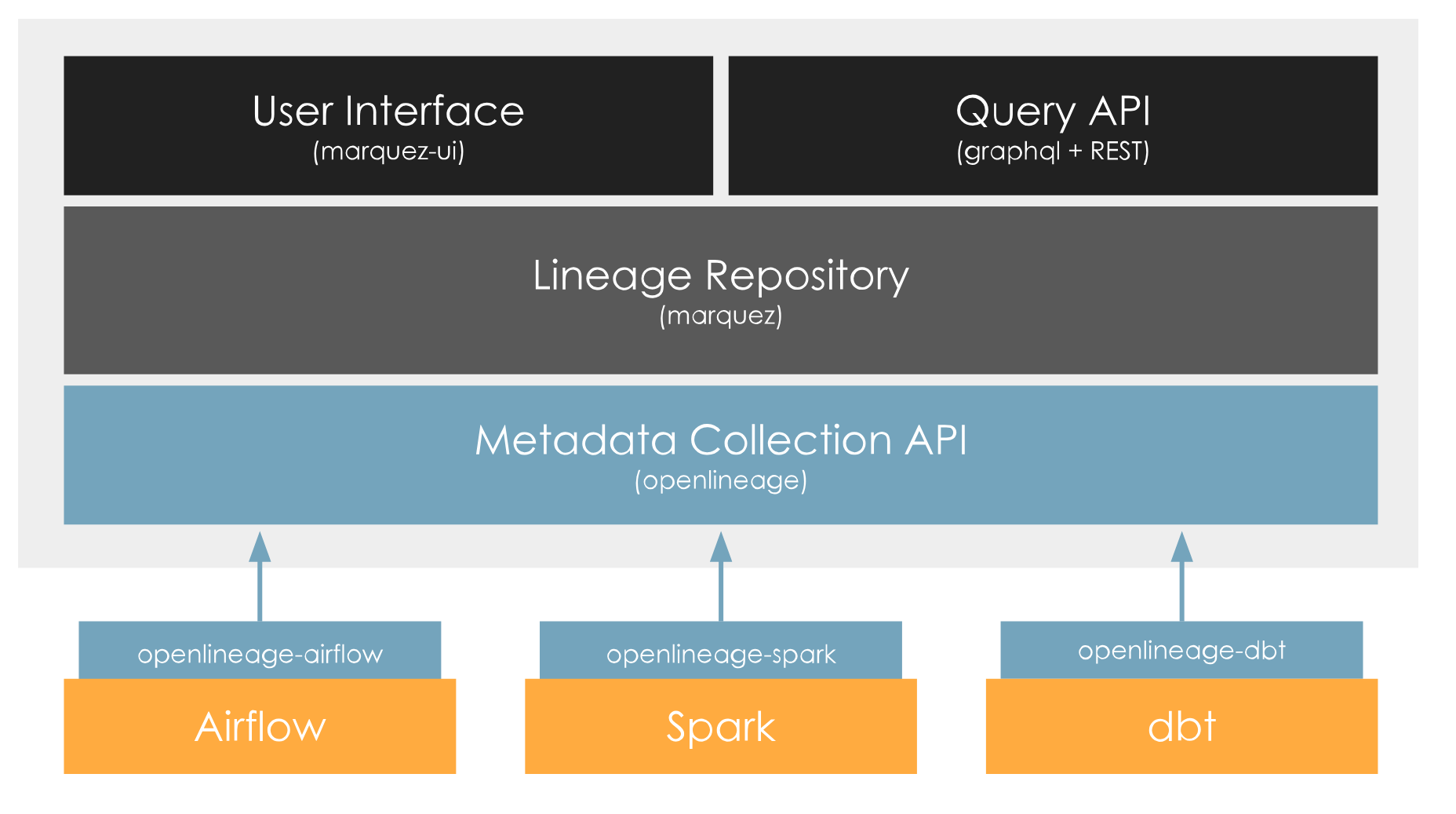
以下是OpenLineage的基本架构组件:
- API和协议:OpenLineage定义了一组开放的API和协议,用于报告和查询数据血缘信息。这些协议旨在标准化不同工具和平台之间的数据血缘信息交换。
- 客户端库:OpenLineage提供多种编程语言的客户端库,方便用户将OpenLineage集成到他们的ETL工具、数据处理框架或工作流调度器中。这些库负责将数据血缘信息发送到OpenLineage服务器。
- 收集器(Collector):收集器是负责接收来自不同数据工具和平台的血缘信息的组件。它可以作为一个独立的服务运行,也可以嵌入到现有的基础设施中。
- 存储(Backend Storage):收集到的血缘信息需要被持久化存储。OpenLineage可以与多种存储后端集成,包括关系型数据库、NoSQL数据库、或者专用的元数据存储系统。
- 查询接口:OpenLineage提供查询接口,允许用户和工具查询存储的血缘信息。这些接口可以用于生成报告、可视化数据流、进行影响分析等。
- 集成和适配器:OpenLineage提供了一系列适配器和集成模块,帮助用户将其与常见的数据工具(如Apache Airflow、Apache Spark、dbt等)连接。
- 可视化工具:虽然OpenLineage的核心不直接包含可视化工具,但它可以与第三方工具集成,提供数据血缘的可视化和分析功能。
通过这些组件,OpenLineage能够为数据工程师、数据科学家和数据分析师提供一个统一的视图,帮助他们理解数据在系统中的流动、转换和依赖关系。这对于确保数据质量、遵从性和高效的数据管理至关重要。
参考链接:


