在Linux的shell命名使用中,会经常遇到管道操作符,管道操作是一个非常优秀的设计。今天我们就一起深入的学习下。
管道简介
管道,英文为pipe。这是一个我们在学习Linux命令行的时候就会引入的一个很重要的概念。它的发明人是道格拉斯.麦克罗伊,这位也是UNIX上早期shell的发明人。他在发明了shell之后,发现系统操作执行命令的时候,经常有需求要将一个程序的输出交给另一个程序进行处理,这种操作可以使用输入输出重定向加文件搞定,比如:
$ ls -l /etc/ > etc.txt $ wc -l etc.txt 234 etc.txt
但是这样未免显得太麻烦了。所以,管道的概念应运而生。目前在任何一个shell中,都可以使用“|”连接两个命令,shell会将前后两个进程的输入输出用一个管道相连,以便达到进程间通信的目的:
$ ls -l /etc/ | wc -l 234
对比以上两种方法,我们也可以理解为,管道本质上就是一个文件,前面的进程以写方式打开文件,后面的进程以读方式打开。这样前面写完后面读,于是就实现了通信。实际上管道的设计也是遵循UNIX的“一切皆文件”设计原则的,它本质上就是一个文件。Linux系统直接把管道实现成了一种文件系统,借助VFS给应用程序提供操作接口。
虽然实现形态上是文件,但是管道本身并不占用磁盘或者其他外部存储的空间。在Linux的实现上,它占用的是内存空间。所以,Linux上的管道就是一个操作方式为文件的内存缓冲区。
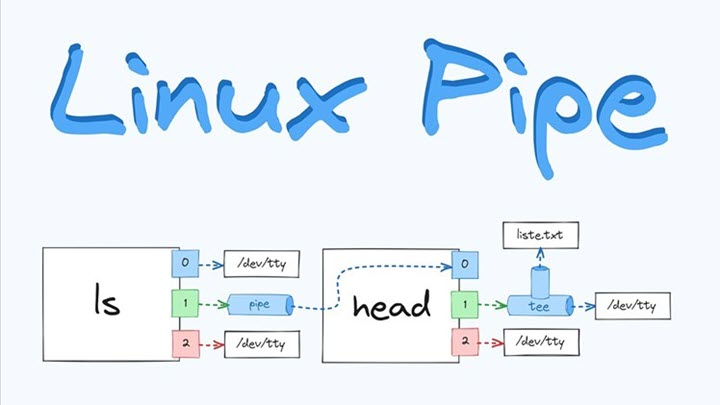
基本概念:
- 管道是一种特殊的文件类型,允许一个进程的输出直接作为另一个进程的输入。
- 管道在Unix中通常用竖线符号 | 表示。
工作原理:
- 当创建一个管道时,操作系统会创建一个缓冲区,用于存储从管道一端传入的数据,直到另一端的进程读取这些数据。
- 管道是单向的,数据只能从一个方向流动。
使用场景:
- 管道广泛用于Unix中的命令行操作,通过管道可以将多个命令串联起来,形成一个命令链。
- 例如,ls | grep “txt”命令会先列出当前目录的所有文件和目录,然后通过管道传递给 grep 命令,后者只输出包含”txt”的行。
优点:
- 简化了进程间的通信。
- 增加了命令的灵活性和强大的组合能力。
- 促进了小型、专用程序的使用。
局限性:
- 由于管道是单向的,为了实现双向通信,需要创建两个管道。
- 管道中的数据是暂时的,一旦被读取,就会从管道中消失。
如果说Unix是计算机文明中最伟大的发明,那么,Unix下的Pipe管道就是跟随Unix所带来的另一个伟大的发明。管道所要解决的问题,还是软件设计中老生常谈的设计目标——高内聚,低耦合。它以一种“链式模型”来串接不同的程序或者不同的组件,让它们组成一条直线的工作流。管道是一种高效的进程间通信机制,它通过连接多个命令和程序,使得用户可以构建复杂的数据处理操作。
重定向和管道的区别
乍看起来,管道也有重定向的作用,它也改变了数据输入输出的方向,那么,管道和重定向之间到底有什么不同呢?简单地说:
- 重定向操作符 > 将命令与文件连接起来,用文件来接收命令的输出;
- 管道符 | 将命令与命令连接起来,用第二个命令来接收第一个命令的输出。
如下所示:
command > file command1 | command1
管道命令
学习管道之前我们先了解一下linux的命令执行顺序。通常情况下,我们在终端只能执行一条命令,然后按下回车执行,那么如何执行多条命令呢?
- 顺序执行多条命令:command1; command2; command3; 简单的顺序指令可以通过;来实现
- 有条件的执行多条命令:which command1 && command2 || command3
- &&: 如果前一条命令执行成功则执行下一条命令,如果command1执行成功(返回0),则执行command2
- ||: 与&&命令相反,执行不成功时执行这个命令
- $?: 存储上一次命令的返回结果
举例:
$ which git > /dev/null && git --help //如果存在git命令,执行git --help命令 $ echo $?
管道是一种通信机制,通常用于进程间的通信(也可通过socket进行网络通信),它表现出来的形式将前面每一个进程的输出(stdout)直接作为下一个进程的输入(stdin)。管道命令使用|作为界定符号,管道命令与上面说的连续执行命令不一样。
- 管道命令仅能处理standard output, 对于standard error output会予以忽略。less, more, head, tail…都是可以接受standard input的命令,所以他们是管道命令。ls, cp, mv并不会接受standard input的命令,所以他们就不是管道命令了。
- 管道命令必须要能够接受来自前一个命令的数据成为standard input继续处理才行。
第一个管道命令
$ ls -al /etc | less
通过管道将ls -al的输出作为下一个命令less的输入,方便浏览。
以less结束的管道(或more,这是个相似的标签页工具)是最常被使用的。这让用户可以阅览尚未显示的大量文字(受可用缓存限制,控制台的屏幕大小、屏幕缓存大小往往有限,不足以一次先输出所有输出内容,也不能自由滚动内容),若少了这工具则这些文字将会卷过终端而无法阅读到。换句话说,他们将程序员从为自己的软件开发分页器的负担中解放了出来:他们只需要把他们的输出用过“管道”导入到less程序中即可,甚至也可以完全不顾分页问题,去假定他们的用户会在需要将输出分页的时候自己去这样做。
选取命令: cut. grep
cut: 从某一行信息中取出某部分我们想要的信息。
- cut -d ‘分隔字符’ -f field:根据-d将信息分隔成数段,-f后接数字表示取出第几段
- cut -c 字符范围。以字符为单位取出固定字符区间的信息
## 打印/etc/passwd文件中以:为分隔符的第1个字段和第6个字段分别表示用户名和家目录 # cat etc/passwd | cut -d ':' -f 1,6 ## 打印/etc/passwd文件中每一行的前10个字符: # cat /etc/passwd | cut -c 1-10
grep: 分析一行信息,如果其中有我们需要的信息,就将该行拿出来
grep [-acinv] [–color=auto] ‘查找字符串’ filename
- -a: 将binary文件以text文件的方式查找数据
- -c: 计算找到’查找字符串’的次数
- -i: 忽略大小写的不同
- -n: 输出行号
-v: 反向选择,显示没有查找内容的行 - –color=auto: 将找到的关键字部分加上颜色显示
示例:
## 取出含有 fanco 的 /etc/passwd 文件的行 # cat etc/passwd | grep -n -c 'fanco' # cat etc/passwd | grep -n 'fanco' # cat etc/passwd | grep -n -v 'fanco'
排序命令:sort, wc, uniq
sort
sort [-fbMnrtuk] [file or stdin]
- -f:忽略大小写的差异,例如 A 与 a 视为编码相同
- -b:忽略最前面的空格部分
- -M:以月份的名字来排序,例如 JAN, DEC 等等的排序方法
- -n:使用『纯数字』进行排序默认是以文字型态来排序的)
- -r:反向排序
- -u:就是 uniq,相同的资料中,仅出现一行代表
- -t:分隔符号,预设是用 [tab] 键来分隔
- -k:以那个区间 (field) 来进行排序的意思
示例:
## 对 /etc/passwd 的账号进行排序 # cat /etc/passwd | sort ## 通过 /etc/passwd 第 5 列来进行排序 # cat etc/passwd | sort -t ':' -k 3 ## 这里排序还是按照文字进行排序的,切换成数字排序 # cat etc/passwd | sort -t ':' -k 3 -n
uniq
uniq [-ic]
- -i:忽略大小写的不同
- -c:进行计数
示例:
## 使用 last 取出历史登录信息的账号,排序,去重 # last | cut -d ' ' -f 1 | sort | uniq -c
wc
- wc [-lwm]
- -l:仅列出行
- -w:仅列出多少字(英文单字)
- -m:多少字符
示例:
## 查看 etc/passwd 中有多少账号 # cat /etc/passwd | wc -l ## 计算最近登录系统的人次 # last | grep [a-zA-Z] | grep -v 'wtmp' | wc -l ## 查看某个文件的行数字数字符数 # cat etc/passwd | wc
双向重定向命令:tee
tee:在数据流的处理过程中将某段信息保存下来,使其既能输出到屏幕又能保存到某一个文件中。
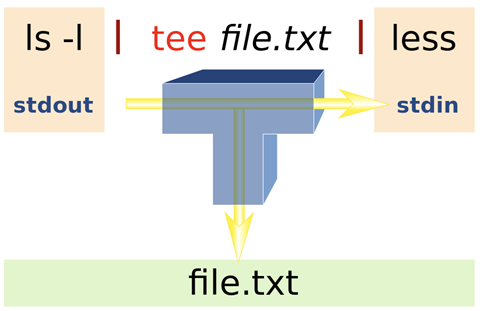
tee [-a] file
- -a: 以累加的方式,将数据加入 file 中
示例:
## 查询最近用户登录情况,并将其保存到文件中 # last | tee info | cut -d ' ' -f 1 # less info
如果 tee 后接的文件已存在,内容会被覆盖掉,加上 -a 参数则会累加
字符转换命令:tr, col, join, paste, expand
tr:用来删除一段信息当中的文字,或者进行文字信息得替换
tr [-ds] set
- -d: 删除信息当中的 set1 这个字符串
- -s: 替换掉重复的字符
示例:
## 将上一步生成的 info 文件删除掉所有的 root # cat info | tr -d 'root' ## 删除时并不是只删除连续的字符,reboot 也被删除掉了 root 部分 ## 除去 dos 文件留下来的 ^M 符号,^M 可以用 \r 替代 $ cat /root/passwd | tr -d '\r' > /root/passwd.linux
col
col 经常被用于将 manpage 转存为纯文本文件
col [-xb]
- -x:将 tab 键换成对等的空格键
- -b: 在文字内有反斜杠 (/) 时,仅保留反斜杠最后接的那个字符
示例:
## 将上图中的 ^I 换成空格键 # cat info | col -x | cat -A | more
join: 主要讲两个文件有相同数据的一行, 相同字段放在前面
join [-ti12] file1 file2
- -t: join 默认以空格符分隔数据,并且对比第一个字段的数据, 如果两个文件相同,则将两条数据连成一行
- -i: 忽略大小写的差异
- -1: 说明第一个文件通过那个字段来进行分析
- -2: 说明第二个文件通过那个字段来分析
示例:
## 将 /etc/passwd 与 /etc/shadow 相关数据整合成一列 # head -3 /etc/passwd /etc/shadow ## 将 etc/passwd 按:分隔的第 4 个字段与 etc/group 的第 3 个字段比较,如果相同,则将他两同行数据放在一起 # join -t ':' -1 4 /etc/passwd -2 3 /etc/group
paste: 直接将两个文件两行贴在一起,中间以 [tab] 键隔开
paste [-d] file1 file2
- -d: 后面可以接分隔字符,默认以 [tab] 来分隔的
- -: 如果 file 部分写成 -,表示接受 standard input 数据的意思
示例:
# paste info info2
expand: 把 tab 键转为空格键
expand [-t] file
- -t: 后面接数字,一般,一个 tab 可以用 8 个空格代替,可以自行定义代表几个空格
示例:
# cat info | expand -3 info
切割命令:split
split:顾名思义,讲一个大文件依据文件大小或行数切割成为小文件
- split [-bl] file prefix
- -b: 后面可接欲切割文件的大小,可加单位,例如 b, k, m 等
- -l: 以行数来进行切割
- PREFIX: 代表前导符,可作为切割文件的前导文字
示例:
$ split -b 300K /etc/passwd
管道的原理
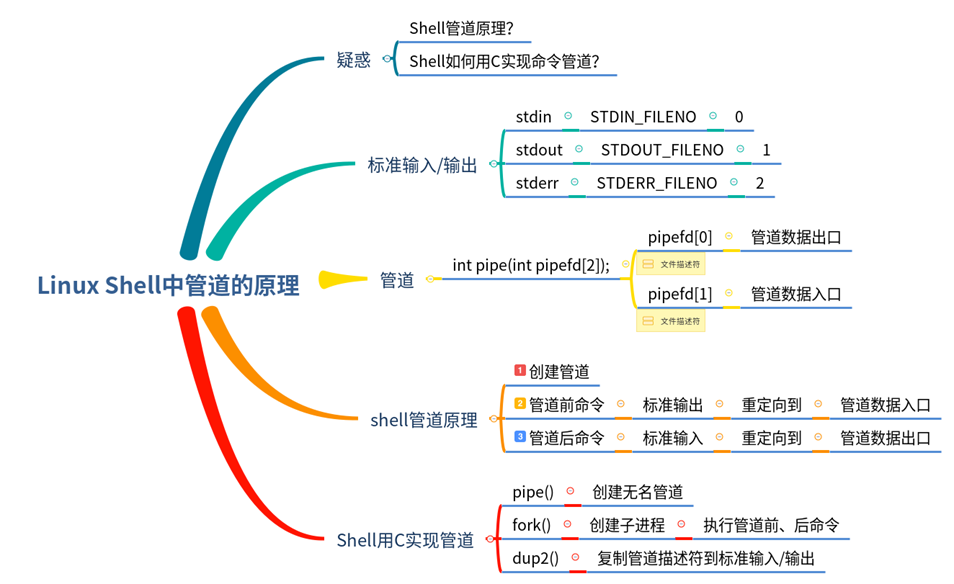 Shell中通过fork+exec创建子进程来执行命令。如果是含管道的Shell命令,则管道前后的命令分别由不同的进程执行,然后通过管道把两个进程的标准输入输出连接起来,就实现了管道。
Shell中通过fork+exec创建子进程来执行命令。如果是含管道的Shell命令,则管道前后的命令分别由不同的进程执行,然后通过管道把两个进程的标准输入输出连接起来,就实现了管道。
例如:
grep "error" minicom.log | awk '{print $1}'
这句命名的作用非常简单,
- 通过grep命令在log中检索含有error关键字的行
- 通过awk命令打印grep的输出结果中每一行的第一个字段
在Shell中要实现这样的效果,有4个步骤:
- 创建pipe
- fork两个子进程执行grep和awk命令
- 把grep子进程的标准输出、标准错误重定向到管道数据入口
- 把awk子进程的标准输入重定向到管道数据出口
这样就实现了Shell管道:grep把结果输出到管道,awk从管道获取数据。
PIPE和FIFO
PIPE(管道)和FIFO(先进先出队列)都是在Unix和类Unix系统中用于进程间通信的机制,但它们在工作方式和用途上有一些区别:
PIPE(管道)
定义:PIPE是一种典型的Unix进程间通信机制,允许数据流从一个进程流向另一个进程。
特点:
- 通常是匿名的,即没有具体的文件名与之关联。
- 主要用于父子进程或者相关进程之间的通信。
- 是半双工的通信方式,数据只能单向流动。
- 通常在命令行中使用管道符号|创建,例如ls | grep txt。
FIFO(先进先出队列)
定义:FIFO,也称为命名管道,是一种特殊类型的文件,用于在不相关的进程之间进行通信。
特点:
- 与PIPE不同,FIFO有具体的文件名,位于文件系统中。
- 可以被不相关的进程打开进行读写,实现进程间通信。
- 也是半双工的通信方式,但可以通过创建两个FIFO文件来实现全双工通信。
- 使用mkfifo命令在Unix系统中创建。
对比
- 应用场景:PIPE通常用于有关联的进程(如父子进程)之间的通信,而FIFO用于不相关的进程间通信。
- 创建方式:PIPE是在进程创建时由操作系统隐式创建的,通常用于临时通信;FIFO是显式创建在文件系统中的,适用于更持久的通信需求。
- 命名:PIPE一般是匿名的,而FIFO有具体的文件名。
- 通信方式:两者都是半双工通信,但FIFO可以通过创建两个命名管道来模拟全双工通信。
总的来说,虽然PIPE和FIFO在基本原理上相似(都是基于管道的通信机制),它们在使用场景和实现方式上各有特点。PIPE适用于临时、快速的通信,特别是在有关联的进程之间;而FIFO则更适用于长期、稳定的通信,特别是在不相关的进程之间。


