Kestra简介
Kestra是一个现代化的开源工作流编排工具,专注于数据处理和自动化任务的管理。它旨在简化复杂数据工作流的构建、调度和监控。
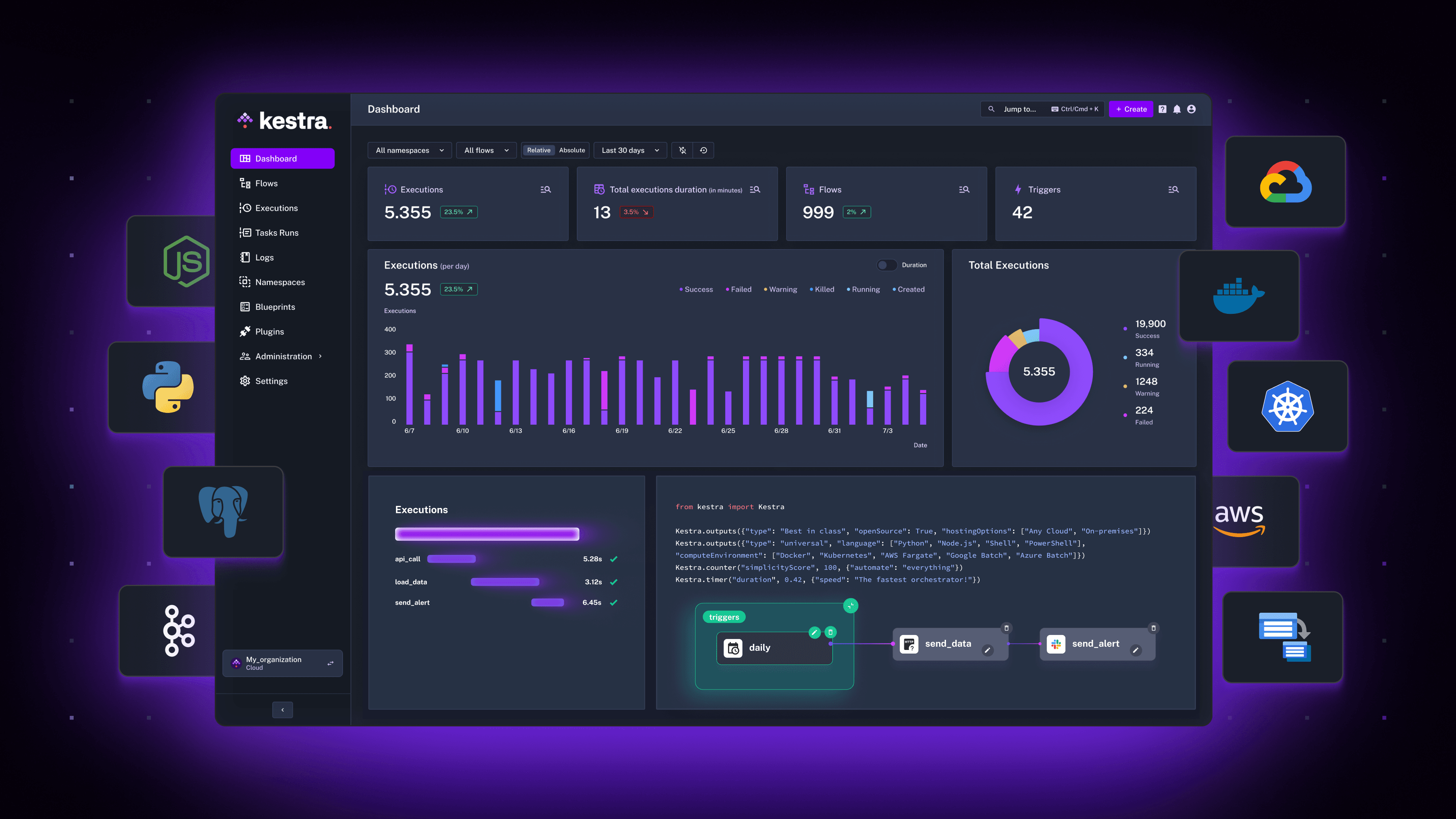
核心概念
- 工作流(Workflow):Kestra的工作流是由多个任务(Task)组成的有向无环图(DAG)。工作流定义了任务的执行顺序和依赖关系。
- 任务(Task):任务是工作流的基本执行单元,可以是数据处理、文件操作、HTTP请求等。Kestra支持多种类型的任务,包括脚本执行、数据传输、API调用等。
- 触发器(Trigger):触发器用于自动启动工作流,可以基于时间调度(如Cron表达式)或事件驱动(如文件到达、消息队列事件等)。
- 插件(Plugin):Kestra提供了丰富的插件系统,允许用户扩展其功能和集成能力。插件可以用于自定义任务类型、连接外部系统和数据源。
- 存储和日志(Storage and Logs):Kestra使用分布式存储系统来管理任务的输出和日志信息,确保数据的可靠性和可追溯性。
功能特点
- 直观的用户界面:Kestra提供了一个功能全面的Web UI,用户可以通过界面设计、调度和监控工作流,查看任务的执行状态和日志。
- 灵活的调度和触发机制:支持基于时间的调度(Cron)和事件驱动的触发器,满足不同场景的自动化需求。
- 强大的插件系统:提供了多种内置插件,支持与各种数据源和服务的集成,如数据库、消息队列、云存储等。
- 分布式架构:Kestra采用分布式架构设计,支持高并发和大规模数据处理任务,适合在云环境和集群中部署。
- 易于扩展和集成:用户可以通过开发自定义插件和任务类型来扩展Kestra的功能,适应特定的业务需求。
- 可靠的任务执行和错误处理:提供自动重试和错误处理机制,确保任务执行的可靠性和稳定性。
适用场景
- 数据工程:适合构建和管理复杂的数据管道,支持多种数据处理和转换任务。
- 自动化运维:用于自动化运维任务的调度和执行,如备份、监控和报告生成。
- 事件驱动应用:支持事件驱动的工作流,适用于响应外部事件的自动化流程。
Kestra的使用
使用Kestra来管理和编排工作流涉及几个关键步骤,从安装到定义工作流,再到运行和监控。以下是使用Kestra的基本指南:
安装Kestra
Kestra可以通过Docker快速安装和启动。以下是使用Docker启动Kestra的基本步骤:
docker run -d --name kestra -p 8080:8080 kestra/kestra
这个命令将启动Kestra并在本地的8080端口上运行。
定义工作流
Kestra的工作流是通过YAML文件定义的。一个简单的工作流示例如下:
id: example_workflow
namespace: example
tasks:
- id: hello_world
type: io.kestra.core.tasks.scripts.Bash
script: echo "Hello, Kestra!"
在这个示例中,我们定义了一个简单的Bash任务,该任务将在工作流执行时输出”Hello, Kestra!”。
上传和运行工作流
将工作流YAML文件上传到Kestra的Web UI:
- 访问Kestra Web UI,通常在http://localhost:8080。
- 在界面中导航到工作流管理页面。
- 上传定义好的YAML文件。
在Web UI中,你可以手动启动工作流并查看其执行状态和日志。
使用触发器
Kestra支持多种触发器,用于自动化工作流的调度。以下是一个基于时间的触发器示例:
triggers:
- type: io.kestra.core.models.triggers.types.Schedule
cron: "0 0 * * *" # 每天午夜运行
通过在工作流定义中添加触发器,可以实现自动化的定期调度。
监控和日志
Kestra提供了一个全面的Web UI,用于监控工作流的执行情况。你可以查看:
- 工作流的执行状态
- 各个任务的执行日志
- 错误和重试信息
这些信息有助于调试和优化工作流。
扩展和集成
Kestra支持通过插件系统扩展功能和集成外部系统。你可以:
- 开发自定义插件来支持特定的任务类型或数据源
- 使用现有插件与数据库、消息队列、云存储等服务集成
部署
Kestra采用分布式架构设计,可以在本地环境、云平台或容器化环境中部署。为生产环境部署时,建议配置高可用性和持久化存储,以确保数据的可靠性和系统的稳定性。
与Dagster的对比
Kestra和Dagster都是现代化的工作流编排工具,专注于管理和调度数据管道和自动化任务。虽然它们有相似的目标,但在设计理念、功能特性和适用场景上有一些区别。以下是Kestra和Dagster的详细对比:
| 特性/方面 | Kestra | Dagster |
| 开发背景 | Kestra是一个开源的工作流编排工具,专注于自动化任务和数据处理 | Dagster是一个开源的数据工作流编排工具,专注于数据管道的开发和测试 |
| 核心概念 | 基于任务(Task)和工作流(Workflow),支持触发器和插件系统 | 基于实体(Solids)和管道(Pipelines),支持强类型和资源管理 |
| 用户界面 | 提供功能全面的Web UI,用于设计、调度和监控工作流 | 提供直观的Web UI(Dagit)用于监控和调试管道 |
| 调度能力 | 支持基于时间的调度(Cron)和事件驱动的触发器 | 支持定期调度和事件驱动调度,灵活的模式和资源配置 |
| 扩展性 | 强大的插件系统,允许自定义任务类型和集成外部系统 | 支持用户定义的类型和资源,易于与外部系统集成 |
| 任务定义 | 使用YAML文件定义任务和工作流,支持多种任务类型 | 使用Python装饰器定义实体和管道,支持强类型和资源配置 |
| 动态任务生成 | 支持通过触发器和插件实现动态任务生成 | 支持通过实体间的依赖关系管理任务执行顺序 |
| 错误处理 | 提供自动重试和错误处理机制 | 提供详细的错误报告和调试工具 |
| 云原生支持 | 分布式架构设计,适合在云环境和集群中部署 | 支持 Kubernetes 等云原生环境,适合容器化部署 |
| 社区和支持 | 拥有活跃的开源社区和丰富的文档资源 | 拥有活跃的开源社区和丰富的文档资源 |
| 适用场景 | 适合自动化任务调度和管理,尤其是事件驱动和批处理任务 | 复杂的数据管道和工作流,特别适合数据工程和数据科学项目 |
总结
- Kestra:Kestra以其灵活的任务定义和强大的插件系统著称,适合处理各种自动化任务和数据处理工作流。其分布式架构和事件驱动能力使其在云环境和大规模任务管理中表现出色。
- Dagster:Dagster更加专注于数据工程和数据科学领域,提供了强类型支持和资源管理,适合构建和管理复杂的数据管道。其直观的编程模型和强大的调试工具使其在开发和测试过程中具有优势。
选择合适的工具通常取决于具体的需求和项目环境。如果项目涉及复杂的数据工作流和需要强类型支持,Dagster 可能是更好的选择。而对于需要灵活的任务调度和广泛集成能力的场景,Kestra 则可能更为合适。
参考链接:


