文章内容如有错误或排版问题,请提交反馈,非常感谢!
Apache Ignite简介
Apache Ignite是一个分布式数据库、内存缓存和计算平台,旨在提供高性能、高可用性和可扩展性的实时数据处理能力。它可以在内存中存储和处理数据,从而显著提高数据访问速度和计算效率。
产生背景
Apache Ignite的产生背景可以追溯到对高性能计算和大规模数据处理需求的日益增长。以下是一些关键背景因素,推动了Apache Ignite的发展和演变:
- 大数据时代的到来
- 数据量的爆炸性增长:随着互联网、移动设备、物联网等技术的发展,企业和组织产生和收集的数据量呈指数级增长。这种趋势催生了对能够快速存储、处理和分析海量数据的技术的需求。
- 实时数据处理的需求:传统的批处理系统已经无法满足许多应用对实时数据处理的需求。企业需要能够在数据生成的瞬间进行分析和决策,以保持竞争力。
- 内存计算的兴起
- 硬件成本的降低:随着内存和处理器成本的下降,内存计算(In-Memory Computing)成为可行的解决方案。内存计算通过在内存中存储和处理数据,显著提高了数据访问速度和计算效率。
- 内存技术的进步:新的内存技术和更高容量的内存模块使得在内存中存储大量数据成为可能,为内存计算平台的发展奠定了基础。
- 分布式系统的需求
- 可扩展性和高可用性:企业需要能够动态扩展的系统,以适应不断增长的数据和用户需求。分布式系统通过将数据和计算分布在多个节点上,实现了高可用性和可扩展性。
- 容错能力:分布式架构提供了更好的容错能力,确保系统能够在硬件或网络故障的情况下继续运行。
- Apache Ignite的起源
- GridGain的贡献:Apache Ignite最初由GridGain Systems开发,作为一个商用的内存计算平台。为了推动技术的普及和发展,GridGain在2014年将其核心代码捐赠给Apache软件基金会,从而诞生了Apache Ignite项目。
- 开源社区的支持:作为Apache软件基金会的项目,Ignite得到了开源社区的积极贡献和支持,迅速发展成为一个成熟的内存计算平台。
- 应用场景的多样化
- 广泛的应用场景:Apache Ignite被设计为一个通用的内存计算平台,适用于多种应用场景,包括实时数据分析、内存数据库、分布式缓存和流处理等。
- 企业级需求:许多企业在寻找能够满足其高性能和高可用性需求的解决方案时,发现Apache Ignite提供了灵活性和强大的功能集。
Apache Ignite的产生和发展反映了技术趋势和市场需求的变化。它通过提供一个高性能、可扩展和可靠的内存计算平台,帮助企业应对大数据时代的挑战,并在实时数据处理和分析领域发挥重要作用。
核心功能
- 内存计算:
- 支持将数据加载到内存中进行处理,以提高数据访问速度。
- 提供内存中的数据网格和分布式缓存功能,支持事务和SQL查询。
- 分布式存储:
- 支持将数据分布存储在集群的多个节点上,确保高可用性和数据冗余。
- 提供持久化存储选项,以确保数据在节点故障或重启后不会丢失。
- SQL支持:
- 支持ANSI SQL-99标准,允许用户通过SQL查询进行数据访问和操作。
- 提供分布式SQL查询引擎,支持复杂查询和数据分析。
- 计算功能:
- 支持分布式计算任务的执行,包括MapReduce和分布式流处理。
- 提供对机器学习算法的支持,通过集成Apache Ignite Machine Learning模块实现。
- 事务支持:
- 支持ACID事务,确保数据一致性和可靠性。
- 提供乐观和悲观事务模式,适应不同的应用需求。
- 集成和互操作性:
- 支持与多种数据库和数据源的集成,如Hadoop、Spark、Kafka等。
- 提供多种语言客户端,包括Java、C++、.NET和Python。
主要特性
- 高可用性和容错性:通过数据复制和分区机制,确保系统的高可用性和故障恢复能力。
- 动态可扩展性:支持动态添加和移除节点,方便扩展集群规模。
- 多种数据模型:支持键值存储、文档存储、关系型数据模型等,灵活适应不同的应用场景。
- 实时流处理:支持实时数据流处理和事件驱动架构。
应用场景
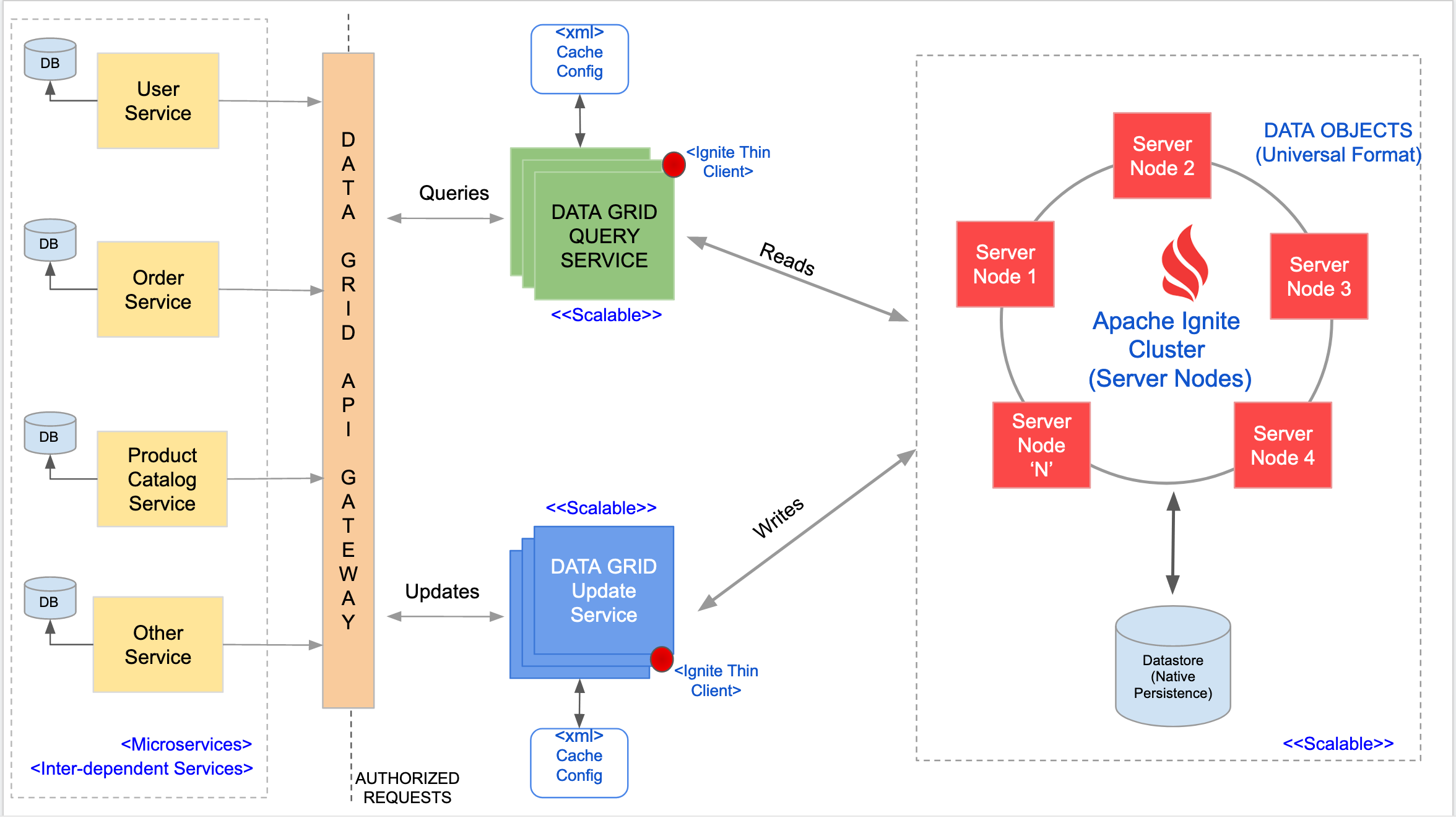
- 实时分析和处理:适合需要实时数据分析和处理的应用,如金融交易、物联网数据处理等。
- 高性能缓存:作为数据库的缓存层,显著提高数据访问速度。
- 分布式计算:支持大规模分布式计算任务的执行,如机器学习模型训练和数据分析。
Apache Ignite和Hazelcast的对比
Apache Ignite和Hazelcast都是流行的内存计算平台,提供分布式缓存、数据网格和计算功能。虽然它们在功能上有许多相似之处,但在设计理念、实现细节和功能特性上存在一些重要区别。以下是对Apache Ignite和Hazelcast的详细对比:
架构和设计
- Apache Ignite:
- 具有内存数据网格和持久化存储的混合架构,支持在内存和磁盘之间的无缝数据操作。
- 提供强大的SQL支持,包括ANSI SQL-99标准。
- 支持ACID事务,适合需要强一致性的场景。
- Hazelcast:
- 主要是一个内存数据网格和缓存解决方案,提供基本的持久化支持。
- 支持分布式对象存储,如Map、Queue、Set等。
- 提供简化的SQL查询支持,但不如Ignite完整。
数据持久化
- Apache Ignite:
- 提供原生的持久化存储,允许在内存和磁盘之间进行数据存储。
- 数据在节点重启后可以自动恢复,无需重新加载。
- Hazelcast:
- 持久化功能主要通过 Hazelcast Jet 或外部数据存储实现。
- 更适合作为缓存层,而非持久化存储。
SQL 支持
- Apache Ignite:
- 强大的 SQL 支持,能够执行复杂的 SQL 查询。
- 支持索引、联接、聚合等高级 SQL 操作。
- Hazelcast:
- 提供基本的 SQL 查询功能,适合简单的查询需求。
- SQL 支持相对有限,适合基础查询。
事务支持
- Apache Ignite:
- 支持分布式 ACID 事务,提供乐观和悲观事务模式。
- 适合需要事务支持的复杂应用场景。
- Hazelcast:
- 支持基本的事务,但不如 Ignite 的事务模型强大。
- 适合简单的事务需求。
计算和处理能力
- Apache Ignite:
- 支持分布式计算、MapReduce 和机器学习。
- 提供丰富的计算 API,适合复杂的计算任务。
- Hazelcast:
- 提供基本的计算功能,如执行分布式任务。
- 计算功能相对简单,适合基本的任务处理。
集成和生态系统
- Apache Ignite:
- 与 Hadoop、Spark、Kafka 等大数据生态系统集成良好。
- 提供多语言客户端支持,包括 Java、.NET、C++ 和 Python。
- Hazelcast:
- 提供多种客户端 API 和语言绑定。
- 集成支持丰富,但与大数据生态系统的集成不如 Ignite 广泛。
易用性和社区
- Apache Ignite:
- 拥有一个活跃的开源社区,丰富的文档和支持资源。
- 学习曲线较陡,适合有经验的开发者。
- Hazelcast:
- 以易用性著称,提供直观的 API 和管理工具。
- 社区活跃,适合快速上手和部署。
选择 Apache Ignite 或 Hazelcast 取决于具体的应用需求:
- Apache Ignite:适合需要强大的 SQL 支持、事务处理和数据持久化的应用,适合复杂的计算和分析任务。
- Hazelcast:适合需要简单易用的内存缓存和数据网格解决方案,适合快速开发和部署。
参考链接:


