文章内容如有错误或排版问题,请提交反馈,非常感谢!
Apache Hama简介
Apache Hama是一个开源的分布式计算框架,主要用于大规模图处理和机器学习任务。它最初是作为Apache软件基金会的一个项目,旨在提供一种高效的计算模型,能够处理大规模的数据集。
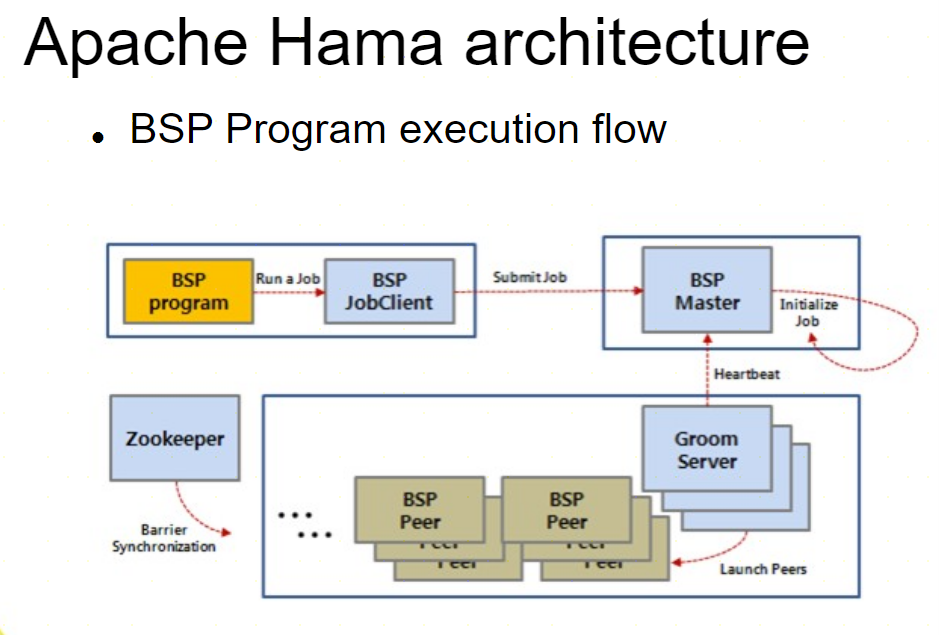
核心特点
- Bulk Synchronous Parallel (BSP)模型:
- Hama基于BSP模型,这是一种并行计算模型,适用于大规模图计算。BSP将计算分为若干个超级步(superstep),每个超级步都包括计算、通信和同步三个阶段。
- 这种模型有助于在分布式环境中实现高效的负载均衡和容错能力。
- 图计算:
- Hama特别适合于图处理任务,如PageRank、最短路径计算、最大流等。
- 提供了对图形数据结构的内置支持,允许用户方便地进行图算法的开发和优化。
- 机器学习:
- 除了图计算,Hama还支持各种机器学习算法的实现,如聚类、分类和协同过滤等。
- 其可扩展性使得用户能够在大规模数据集上进行复杂的机器学习任务。
- 高可扩展性和容错性:
- Hama设计为可以在大规模集群上运行,支持动态扩展。
- 内置的容错机制可以处理节点故障,确保计算任务的可靠性。
- 与Hadoop集成:
- 虽然Hama是一个独立的项目,但它可以与Hadoop生态系统中的其他组件集成,如HDFS(Hadoop分布式文件系统)用于数据存储。
- 这种集成能力使得Hama能够利用现有的Hadoop基础设施来处理大数据任务。
优势和挑战
优势:
- 高效的并行计算模型,适合大规模数据处理。
- 灵活性和可扩展性,使其适用于多种应用场景。
- 与Hadoop的良好集成,便于在现有基础设施上部署。
挑战:
- 相较于MapReduce等模型,BSP模型的编程复杂度可能更高。
- 社区活跃度和生态系统支持可能不如一些更流行的框架。
应用场景
- 社交网络分析:利用图计算能力分析社交网络中的关系和传播模式。
- 大规模机器学习:在大数据集上训练复杂的机器学习模型。
- 科学计算:应用于需要大量并行计算的科学模拟和数据分析任务。
- 推荐系统:利用协同过滤算法进行个性化推荐。
Apache Hama是一个强大的工具,适合需要高性能并行计算的场景,尤其是在图处理和机器学习领域。通过利用BSP模型,它能够在大规模集群上高效地执行复杂的计算任务。
Apache Hama与Spark的对比
Apache Hama和Apache Spark都是用于大规模数据处理的分布式计算框架,但它们在设计目标、使用场景和技术实现上有显著的不同。以下是对这两个框架的详细对比:
计算模型
- Apache Hama:
- 基于Bulk Synchronous Parallel (BSP) 模型。这种模型强调同步的超级步,在每个超级步中,所有并行任务都会进行计算、通信,然后同步。
- 适合于图计算和一些机器学习算法,这些算法通常需要复杂的节点间通信和同步。
- Apache Spark:
- 基于Resilient Distributed Dataset (RDD) 和DAG(有向无环图) 计算模型。RDD提供了数据的不可变性和容错性,而DAG则允许灵活的任务调度和优化。
- 适合于广泛的数据处理任务,包括批处理、流处理、机器学习和图计算等。
应用场景
- Apache Hama:
- 主要用于图处理(如PageRank、最短路径)和需要复杂同步机制的任务。
- 适合科学计算和大规模并行算法的实现。
- Apache Spark:
- 广泛应用于批处理、实时数据流处理(通过Spark Streaming)、机器学习(通过MLlib)、图计算(通过GraphX)和SQL查询(通过Spark SQL)。
- 由于其广泛的库支持,Spark被广泛应用于各种数据分析任务。
性能和扩展性
- Apache Hama:
- 在需要频繁同步的计算任务中表现良好,但其同步开销可能导致在某些任务中性能不如异步模型。
- 设计用于大规模集群,具有良好的扩展性。
- Apache Spark:
- 利用内存计算和DAG优化技术,Spark通常在迭代计算和需要快速响应的任务中表现优异。
- 其内存管理和数据持久化策略允许在内存中进行高效计算,但可能需要较大的内存资源。
易用性和社区支持
- Apache Hama:
- 社区规模较小,相对而言,使用文档和支持资源可能不如Spark丰富。
- 编程模型(BSP)对于不熟悉并行计算的用户可能具有一定的学习曲线。
- Apache Spark:
- 拥有活跃的社区和广泛的文档支持。
- 提供了多种高级API(如DataFrame和Dataset),降低了大数据处理的复杂度。
集成与生态系统
- Apache Hama:
- 可以与Hadoop生态系统集成,使用HDFS进行数据存储。
- 由于其特定的应用场景,生态系统支持相对有限。
- Apache Spark:
- 与Hadoop、Kafka、Cassandra等广泛集成,能够处理来自多种数据源的数据。
- 丰富的库(Spark SQL, MLlib, GraphX, Spark Streaming)使其成为一个通用的大数据处理平台。
总结而言,Apache Hama和Apache Spark各有其优势,选择哪个框架应基于具体的应用需求。Hama更适合于需要复杂同步的并行计算任务,而Spark由于其广泛的库支持和灵活的计算模型,是一个功能全面的通用大数据处理平台。
Apache Hama与Giraph的对比
Apache Hama和Apache Giraph都是基于Bulk Synchronous Parallel (BSP)模型的分布式计算框架,主要用于大规模图处理和某些类型的机器学习任务。尽管它们在很多方面相似,但也有一些关键的区别。以下是Apache Hama和Apache Giraph的详细对比:
计算模型
- Apache Hama:
- 基于 BSP 模型,将计算任务划分为多个超级步(superstep),每个超级步包括计算、通信和同步三个阶段。
- 支持多种数据处理任务,包括图计算和某些机器学习算法。
- Apache Giraph:
- 同样基于 BSP 模型,特别针对图计算进行了优化。
- 采用顶点中心(vertex-centric)的编程模型,每个顶点可以独立执行计算,并与其他顶点通信。
应用场景
- Apache Hama:
- 适用于图计算(如 PageRank、最短路径)和某些机器学习任务。
- 也支持科学计算和大规模并行算法的实现。
- Apache Giraph:
- 主要用于图计算任务,特别是大规模图的处理。
- 适合社交网络分析、推荐系统、图挖掘等应用。
性能和扩展性
- Apache Hama:
- 在需要频繁同步的计算任务中表现良好,但同步开销可能导致在某些任务中性能不如异步模型。
- 设计用于大规模集群,具有良好的扩展性。
- Apache Giraph:
- 优化了图计算的性能,特别是在大规模图数据集上。
- 通过减少通信开销和优化数据传输,提高了处理效率。
- 支持动态分区和负载均衡,进一步提升了扩展性和性能。
易用性和社区支持
- Apache Hama:
- 社区规模相对较小,文档和支持资源可能不如 Giraph 丰富。
- 编程模型(BSP)对于不熟悉并行计算的用户可能具有一定的学习曲线。
- Apache Giraph:
- 拥有较为活跃的社区和丰富的文档支持。
- 提供了更多的示例和教程,帮助用户快速上手。
- 顶点中心的编程模型相对直观,更容易理解和使用。
集成与生态系统
- Apache Hama:
- 可以与 Hadoop 生态系统集成,使用 HDFS 进行数据存储。
- 由于其特定的应用场景,生态系统支持相对有限。
- Apache Giraph:
- 与 Hadoop 生态系统紧密集成,可以使用 HDFS 和 YARN 进行数据存储和资源管理。
- 支持多种输入/输出格式,可以轻松与 Hadoop 的其他组件(如 MapReduce、Hive、Pig)结合使用。
- 提供了丰富的库和工具,支持图算法的开发和优化。
总结
- Apache Hama:
- 适用于需要复杂同步机制的并行计算任务,包括图计算和某些机器学习算法。
- 社区支持和生态系统相对有限,但仍然是一个强大的工具。
- Apache Giraph:
- 专门针对图计算进行了优化,提供了更好的性能和扩展性。
- 拥有活跃的社区和丰富的文档支持,更容易上手和使用。
- 与 Hadoop 生态系统的紧密集成使其成为处理大规模图数据的首选工具。
选择哪个框架应基于具体的应用需求和团队的技术背景。如果主要关注图计算,且需要高性能和丰富的社区支持,Giraph 可能是更好的选择。如果需要处理更广泛的并行计算任务,Hama 也是一个值得考虑的选项。
参考链接:


