文章内容如有错误或排版问题,请提交反馈,非常感谢!
Alluxio简介
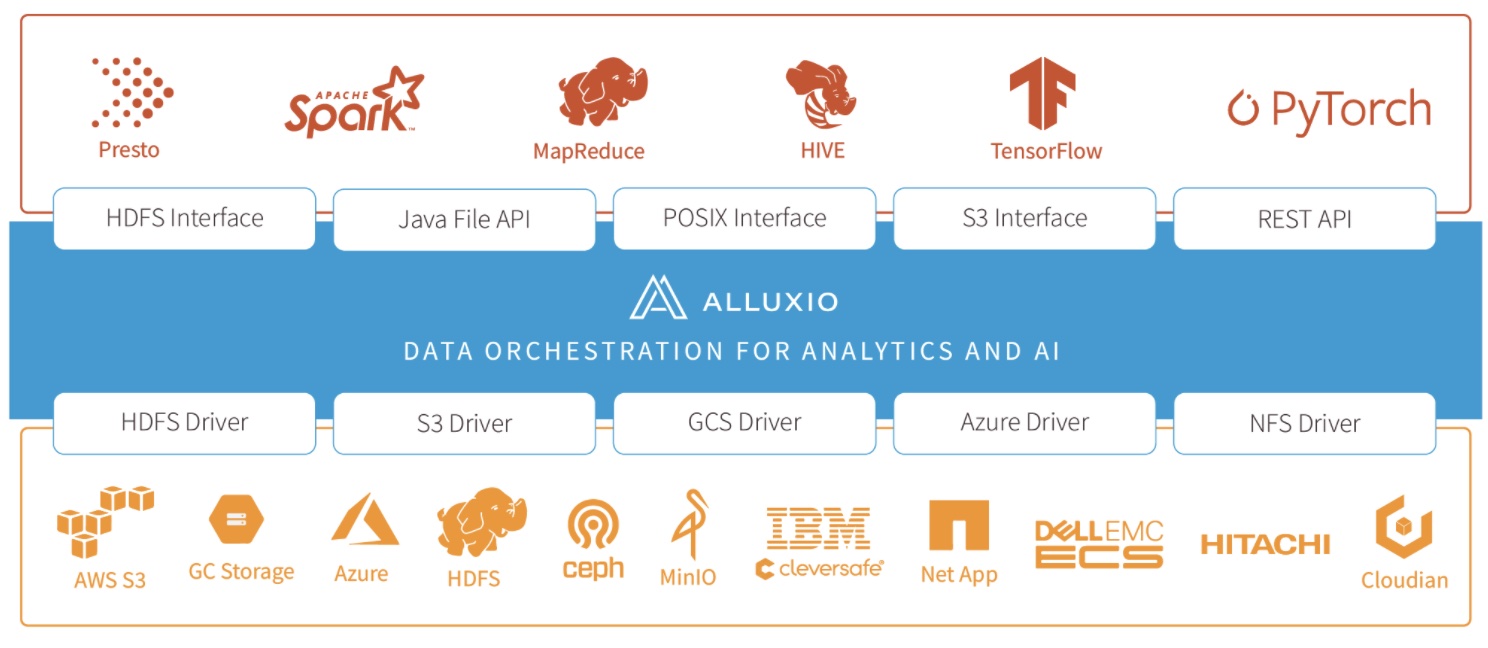
Alluxio(原名Tachyon)是一个开源的虚拟分布式存储系统,旨在桥接计算框架和底层存储系统之间的鸿沟。Alluxio通过提供一个统一的虚拟文件系统接口,使得应用程序可以透明地访问多种存储系统,如HDFS、S3、GCS、Swift等,而无需关心底层存储的具体实现。Alluxio的设计目标是提高数据访问的性能和效率,特别是在大数据和机器学习场景中。
核心特性
- 统一的虚拟文件系统:
- 抽象存储层:Alluxio提供了一个统一的虚拟文件系统接口,使得应用程序可以透明地访问多种存储系统。
- 多存储支持:支持HDFS、S3、GCS、Swift、NFS、Ceph等多种存储系统,方便数据的跨存储访问。
- 高性能数据访问:
- 内存缓存:Alluxio在内存中缓存热点数据,显著提高数据访问速度,减少对底层存储系统的I/O负载。
- 数据本地性:支持数据本地性优化,将计算任务调度到数据所在的节点,减少数据传输开销。
- 数据管理:
- 数据生命周期管理:支持数据的生命周期管理,包括数据的加载、缓存、淘汰和持久化。
- 数据感知调度:根据数据的访问模式和位置,智能调度计算任务,提高整体性能。
- 多计算框架支持:
- 兼容多种计算框架:支持Spark、Hadoop、TensorFlow、Presto等多种计算框架,提供无缝集成。
- 统一命名空间:提供统一的命名空间,使得多个计算框架可以共享同一份数据。
- 高可用性和容错性:
- 主节点冗余:支持主节点的高可用性配置,确保系统的稳定性和可靠性。
- 数据冗余:支持数据的冗余存储,防止单点故障导致的数据丢失。
- 安全性和权限管理:
- 用户认证和授权:支持用户认证和基于角色的访问控制,确保数据的安全性。
- 加密和审计:支持数据加密和审计日志,满足合规性要求。
优势
- 高性能数据访问:通过内存缓存和数据本地性优化,显著提高数据访问速度。
- 统一的虚拟文件系统:提供统一的文件系统接口,支持多种存储系统的透明访问。
- 多计算框架支持:兼容多种计算框架,提供无缝集成和数据共享。
- 高可用性和容错性:支持主节点冗余和数据冗余,确保系统的稳定性和可靠性。
- 灵活的部署选项:支持在云端、本地数据中心或混合环境中部署,适应不同的业务需求。
应用场景
- 大数据分析:
- 适用于需要处理和分析大规模数据的场景,如日志分析、用户行为分析等。
- 通过内存缓存和数据本地性优化,提高数据访问速度和查询性能。
- 机器学习:
- 适用于机器学习和深度学习场景,如模型训练和推理。
- 支持多种存储系统,方便数据的跨存储访问和管理。
- 多计算框架集成:
- 适用于需要集成多种计算框架的场景,如Spark、Hadoop、TensorFlow等。
- 提供统一的命名空间和虚拟文件系统接口,简化数据共享和管理。
- 数据湖和数据仓库:
- 适用于构建数据湖和数据仓库,支持多种存储系统的统一管理和访问。
- 提供高性能的数据访问和管理能力,满足大规模数据存储和分析的需求。
Alluxio是一个强大的虚拟分布式存储系统,通过提供统一的虚拟文件系统接口,桥接了计算框架和底层存储系统之间的鸿沟。Alluxio的设计目标是提高数据访问的性能和效率,特别是在大数据和机器学习场景中。通过内存缓存和数据本地性优化,Alluxio能够显著提高数据访问速度,支持多种存储系统的透明访问和多计算框架的无缝集成。Alluxio是现代数据密集型应用的理想选择。
Alluxio的架构
主要组件
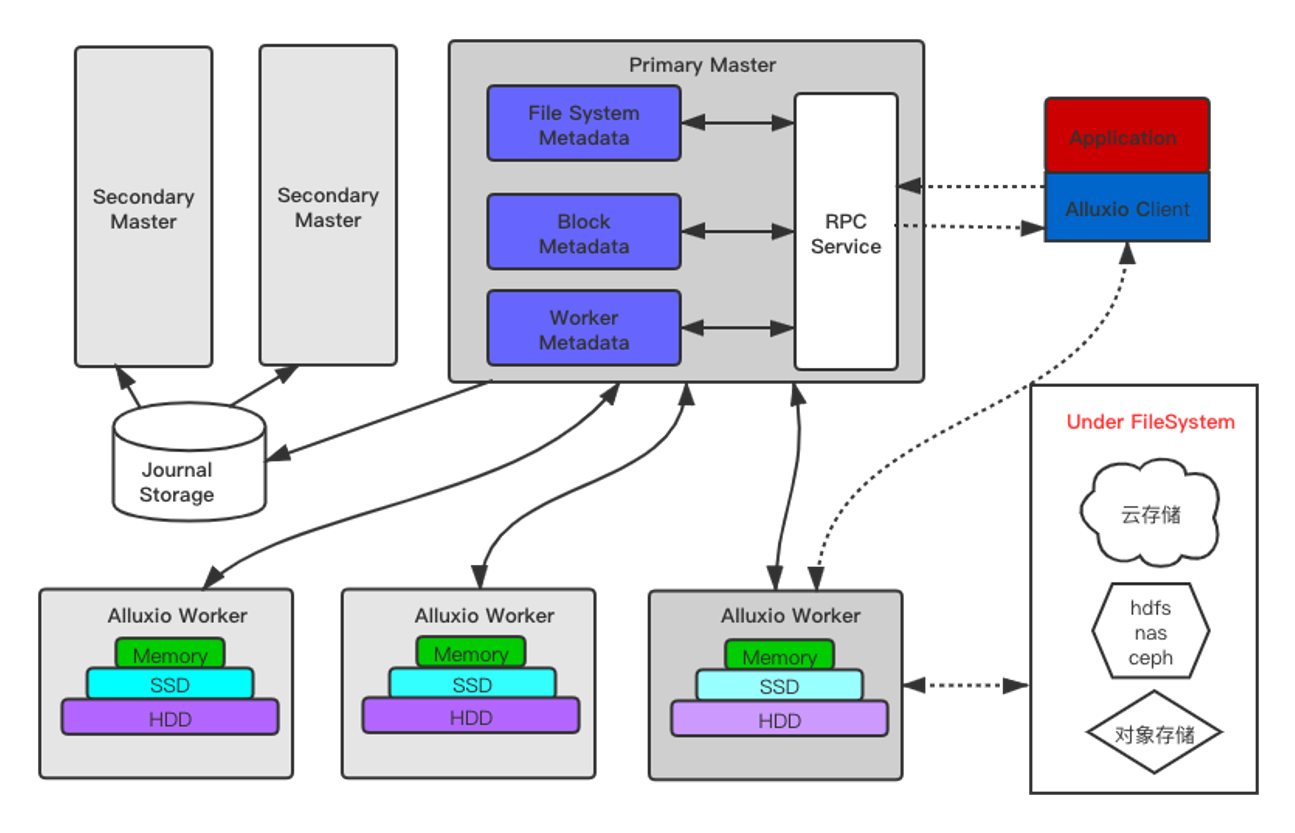
- Master(主节点)
- 元数据管理:Master节点负责管理文件系统的元数据,包括文件和目录的层次结构、文件块的位置信息等。
- 全局协调:Master节点协调整个集群的操作,例如文件的创建、删除、重命名等。
- 容错机制:Master节点维护一个检查点(checkpoint)系统,定期备份元数据,以实现故障恢复。
- Worker(工作节点)
- 数据缓存:Worker节点负责存储和管理数据块。数据块可以存储在内存、SSD或磁盘上,具体取决于配置。
- 数据读写:Worker节点处理客户端的读写请求,将数据缓存到本地存储中,以加速后续访问。
- 心跳机制:Worker节点定期向Master节点发送心跳,报告其状态和可用资源。
- Client(客户端)
- API接口:客户端通过Alluxio提供的API访问数据,这些API类似于Hadoop的FileSystem API。
- 数据访问:客户端首先向Master节点查询数据块的位置,然后直接与Worker节点通信,读取或写入数据。
- Under Storage Systems(底层存储系统)
- 数据持久化:Alluxio支持多种底层存储系统,如HDFS、S3、Google Cloud Storage、Azure Blob Storage等。数据最终会被持久化到这些存储系统中。
- 数据同步:Alluxio可以自动将缓存的数据同步到底层存储系统,确保数据的一致性和持久性。
工作流程
- 启动和初始化:
- Master节点启动并加载元数据。
- Worker节点启动并向Master节点注册,报告其可用资源。
- 数据读取:
- 客户端通过Alluxio API发起数据读取请求。
Master节点返回数据块的位置信息。
- 客户端直接与Worker节点通信,读取数据。
- 如果Worker节点上没有所需数据块,它会从底层存储系统中读取数据,并将其缓存到本地。
- 客户端通过Alluxio API发起数据写入请求。
- Master节点分配一个Worker节点来处理写入操作。
- 客户端将数据写入指定的Worker节点。
- Worker节点将数据缓存到本地,并根据配置策略将数据同步到底层存储系统。
- Worker节点根据配置策略管理本地缓存,例如LRU(最近最少使用)算法。
- 当缓存空间不足时,Worker节点会自动淘汰不常用的数据块。
参考链接:


