文章内容如有错误或排版问题,请提交反馈,非常感谢!
DVC简介
Data Version Control (DVC)是一个开源工具,旨在帮助数据科学家和机器学习工程师管理数据集、模型和实验结果。DVC通过版本控制系统(如Git)来跟踪数据和模型的变化,从而提供了一种有效的方式来管理和复现数据科学项目。
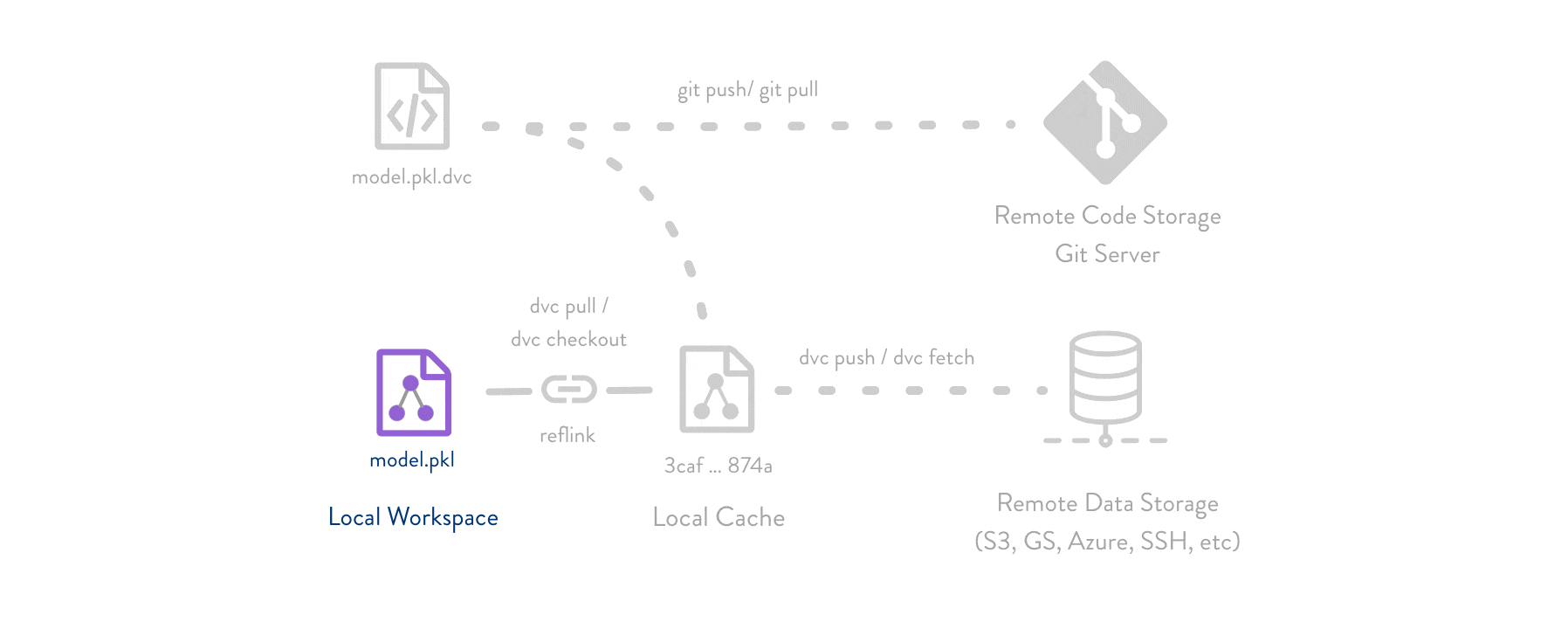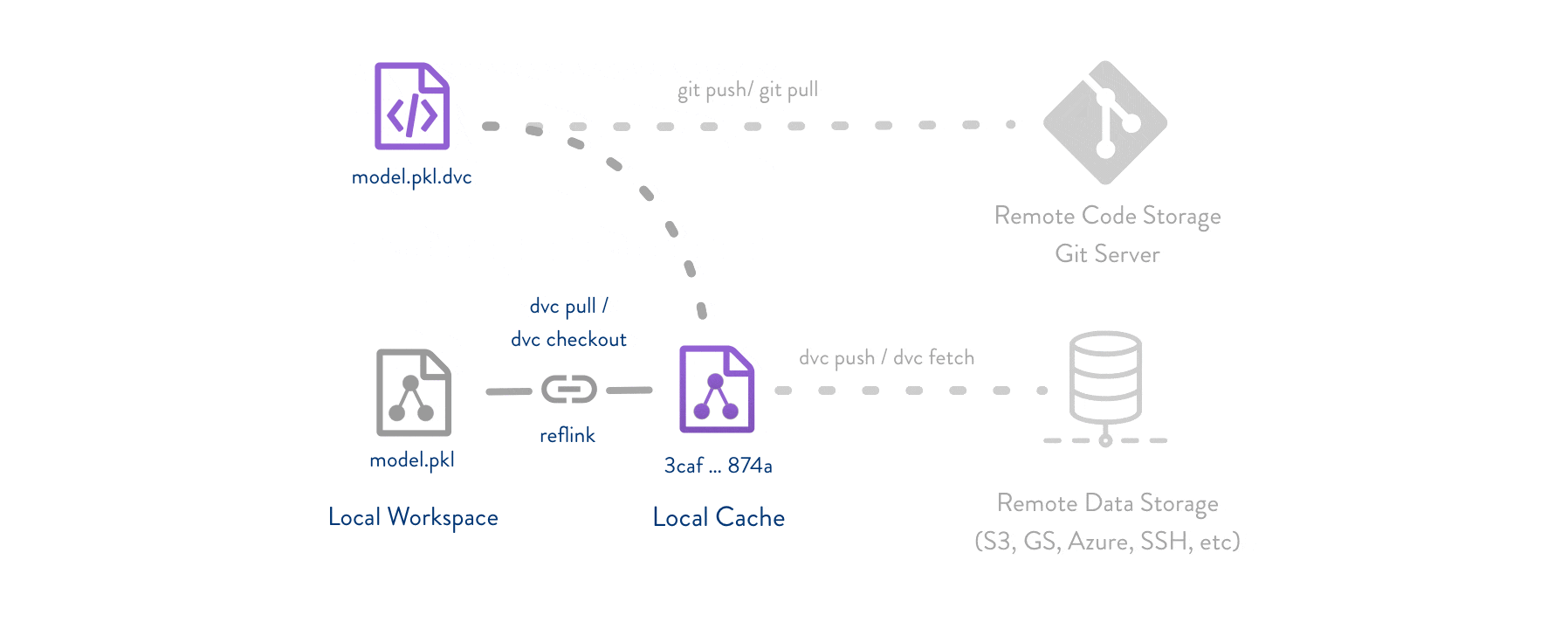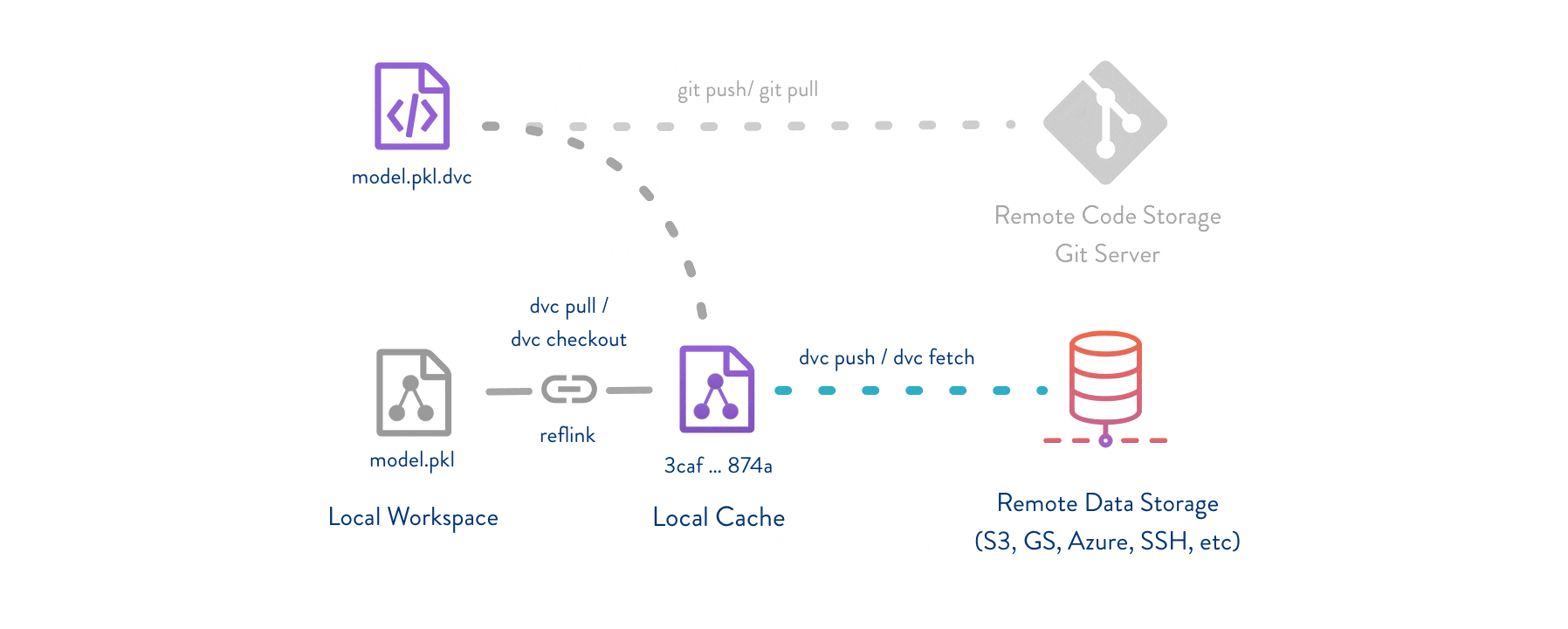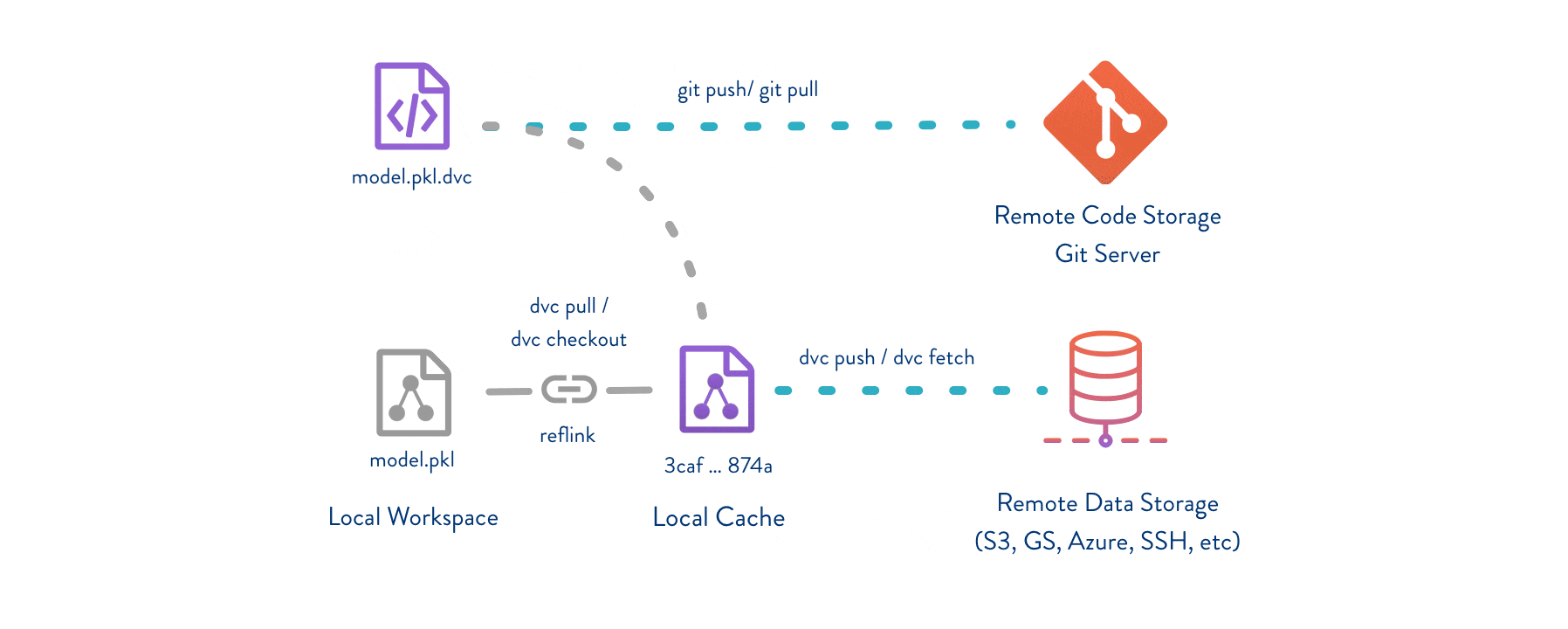
DVC通过元数据管理,提供了一种有效的方式来管理和复现数据科学项目。它结合了版本控制和依赖管理,使得数据科学家和机器学习工程师能够更高效地进行数据处理和模型训练。无论是个人项目还是团队协作,DVC都是一个非常有价值的工具。
核心概念
- 数据版本控制:DVC通过记录数据集和模型的版本,确保每次实验都有明确的历史记录。这有助于团队成员协作和复现实验结果。
- 依赖管理:DVC可以管理数据集、模型和脚本之间的依赖关系,确保每次运行实验时使用正确的输入。
- 管道定义:DVC允许用户定义数据处理和模型训练的管道,通过DVC文件(如yaml)来描述每个步骤及其依赖关系。
优势
- 可复现性:通过记录每个步骤的输入、输出和命令,确保实验的可复现性。
- 协作:团队成员可以通过Git共享和协作,每个人都可以轻松复现其他人的实验结果。
- 自动化:DVC可以自动化数据处理和模型训练的管道,减少手动干预和错误。
- 资源管理:DVC可以帮助管理数据和模型的存储,通过缓存和远程存储来节省本地磁盘空间。
使用场景
- 数据科学项目:管理数据集、特征工程、模型训练和评估。
- 机器学习实验:记录和复现不同的实验配置和结果。
- 团队协作:多人协作时,确保每个人都使用相同的数据和模型版本。
元数据管理
元数据文件
- .dvc文件:每个数据文件或目录在DVC中都有一个对应的.dvc文件,记录了该数据的哈希值、大小、路径等信息。这些文件用于版本控制和数据恢复。
- lock文件:记录了当前项目中所有管道步骤的具体依赖关系和输出,确保每次运行时使用的是相同的输入和配置。
- yaml文件:定义了项目的管道步骤,包括每个步骤的命令、输入、输出和依赖关系。
元数据内容
- 数据哈希:DVC使用SHA-256哈希值来唯一标识每个数据文件或目录。这有助于检测数据的变化并进行版本控制。
- 文件路径:记录数据文件或目录的路径,确保数据的可追溯性。
- 依赖关系:记录每个步骤的输入和输出,以及它们之间的依赖关系。这有助于自动化管道的执行和复现。
- 命令和参数:记录每个步骤的执行命令及其参数,确保实验的可复现性。
DVC的使用
初始化项目
dvc init
这会在项目根目录下创建一个.dvc目录,用于存储DVC的配置和元数据。
添加数据文件
dvc add data.csv
这会创建一个data.csv.dvc文件,记录数据文件的元数据。
定义管道
编辑dvc.yaml文件,定义数据处理和模型训练的管道。例如:
stages:
preprocess:
cmd: python preprocess.py
deps:
- data.csv
outs:
- preprocessed_data.csv
train:
cmd: python train.py
deps:
- preprocessed_data.csv
outs:
- model.pkl
运行管道
dvc repro
这会根据dvc.yaml文件中的定义,依次运行每个步骤,确保所有依赖关系都得到满足。
提交更改
git add . git commit -m "Add data and pipeline"
将元数据文件和管道定义文件提交到Git仓库,以便版本控制和协作。
参考链接:


