文章内容如有错误或排版问题,请提交反馈,非常感谢!
DLT简介
DLT (Data Loading Tool)是一个由DLTHub开发的开源数据加载工具,旨在简化数据从各种来源到目标数据仓库的加载过程。DLT提供了一种高效、灵活且易于使用的方法来构建和管理数据管道。
项目背景
- DLTHub:一家专注于数据集成和数据处理的公司,致力于提供高效、易用的数据加载解决方案。
- DLT:由DLTHub开发的开源项目,旨在简化数据从各种来源到目标数据仓库的加载过程,支持多种数据源和目标,提供强大的数据处理和转换功能。
主要特性
- 多源支持:支持多种数据源,包括但不限于:
- 数据库:MySQL、PostgreSQL、MongoDB、SQL Server等。
- 文件系统:CSV、JSON、Parquet等文件格式。
- API:REST API、GraphQL等。
- 云服务:AWS S3、Google Cloud Storage等。
- 多目标支持:支持多种数据仓库,包括但不限于:
- Amazon Redshift
- Google BigQuery
- Snowflake
- PostgreSQL
- MySQL
- 数据处理与转换
- 强大的数据处理功能:支持数据清洗、转换和聚合等操作。
- SQL支持:使用标准SQL进行数据查询和处理。
- 自定义脚本:支持自定义Python脚本进行复杂的处理逻辑。
- 自动化与调度
- 任务调度:支持定时任务调度,可以按需设置数据加载任务的执行频率。
- 自动化工作流:支持构建自动化工作流,实现数据加载的全流程自动化。
- 灵活的配置
- 配置文件:使用YAML或JSON格式的配置文件来定义数据管道。
- 环境变量:支持使用环境变量来管理敏感信息和配置。
- 监控与日志
- 实时监控:提供实时监控和日志功能,帮助用户随时了解数据加载的运行状态。
- 详细日志:提供详细的日志记录,帮助用户追踪数据加载的过程和结果。
- 社区与生态
- 丰富的插件:支持自定义插件,用户可以根据需求扩展DLT的功能。
- 活跃的社区:有一个活跃的社区,提供支持和贡献。
使用场景
- 数据迁移:在更换数据库或数据仓库时,使用DLT可以快速将数据从旧系统迁移到新系统。
- 数据同步:定期使用DLT进行数据同步,确保不同系统间的数据一致性。
- 数据处理与清洗:利用DLT的数据处理和转换功能,对数据进行预处理、清洗和格式化,以满足后续分析或建模的需求。
- 数据仓库构建:快速构建和管理数据仓库,支持多种数据仓库方案。
- 实时监控:实时监控数据加载的运行状态,及时发现和解决问题。
DLT安装与使用
安装
DLT可以通过多种方式安装,包括源码编译、Docker镜像和二进制包。
源码编译
# 克隆仓库: git clone https://github.com/dlt-hub/dlt.git cd dlt # 安装依赖: pip install -r requirements.txt # 编译和安装: python setup.py install
Docker镜像
# 拉取Docker镜像: docker pull dlt-hub/dlt # 运行Docker容器: docker run -d --name dlt -p 8080:8080 dlt-hub/dlt
二进制包
# 下载二进制包: wget https://github.com/dlt-hub/dlt/releases/download/vX.Y.Z/dlt-vX.Y.Z-linux-amd64.tar.gz tar -xzf dlt-vX.Y.Z-linux-amd64.tar.gz cd dlt-vX.Y.Z-linux-amd64 # 启动DLT: ./dlt start
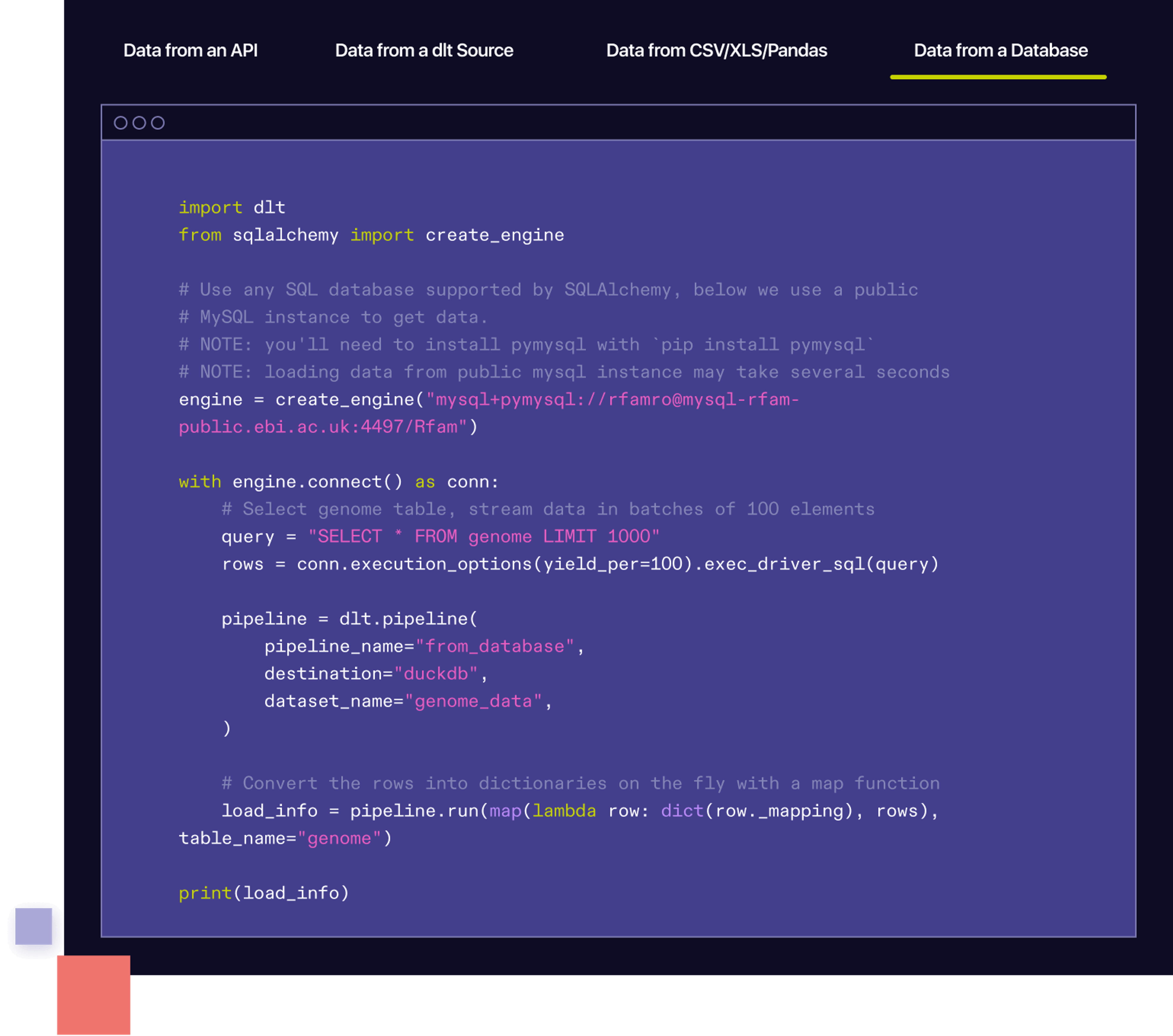
使用示例
配置文件示例
创建一个YAML配置文件pipeline.yaml,定义数据源和目标:
source:
type: postgres
host: localhost
port: 5432
user: user
password: password
database: source_db
table: source_table
target:
type: redshift
host: redshift-cluster-endpoint
port: 5439
user: user
password: password
database: target_db
table: target_table
transformations:
- type: map
fields:
column1: new_column1
column2: new_column2
- type: filter
condition: column1 > 100
运行数据加载
使用配置文件运行数据加载:
dlt load pipeline.yaml
参考链接:


