Airbyte简介
Airbyte是一款开源的数据集成平台,旨在简化从各种数据源到数据仓库的数据管道的创建和管理。作为一个新兴的工具,Airbyte已经迅速获得了广泛的关注和采用,特别是在需要灵活性和可扩展性的场景中。
产生背景
Airbyte是一个开源的数据集成平台,旨在解决数据工程领域中数据集成的复杂性和灵活性问题。其产生背景可以从以下几个方面理解:
- 数据集成的复杂性:随着企业数据源和数据目标的多样化,数据集成变得越来越复杂。企业通常需要将数据从多个来源(如数据库、API、文件存储等)提取到数据仓库、数据湖或分析工具中。这种复杂性导致了对灵活且可扩展的数据集成解决方案的需求。
- 传统ETL工具的局限性:传统的ETL(Extract, Transform, Load)工具通常是闭源的,灵活性有限,难以快速适应新的数据源或目标。它们通常需要复杂的配置和专业的知识,增加了数据集成的时间和成本。
- 开源和社区驱动的需求:在数据工程领域,开源解决方案越来越受到欢迎。开源工具允许社区贡献,促进了创新和快速迭代。Airbyte的出现正是为了填补这一领域的空白,提供一个开源且可扩展的数据集成平台。
- 数据可访问性和民主化:企业希望更多的员工能够访问和使用数据,以便更好地做出数据驱动的决策。这需要一个易于使用的数据集成工具,能够让数据工程师和分析师轻松地将数据连接到他们需要的工具中。
- 技术栈的多样化:现代企业使用的技术栈多种多样,从云服务到本地系统,从SQL数据库到NoSQL存储。这种多样化需要一个能够支持广泛数据源和目标的集成平台。
总之,Airbyte的产生是为了应对现代数据集成的挑战,通过开源和社区驱动的方式提供一个灵活、可扩展且易于使用的数据集成解决方案。
核心特性
- 开源:Airbyte是开源的,允许用户查看、修改和贡献代码。这种透明性和社区驱动的开发模式帮助快速迭代和响应用户需求。
- 可扩展的连接器:
- Airbyte提供了大量开箱即用的数据源和目的地连接器,支持数百种数据源(如数据库、API、文件系统等)。
- 用户可以轻松创建自定义连接器,以满足特定的数据集成需求。
- 基于容器的架构:Airbyte使用Docker容器化技术,这使得其易于部署和管理,同时提高了系统的可移植性和隔离性。
- 灵活的部署选项:支持多种部署环境,包括本地、自托管云环境以及Kubernetes集群。
- 数据同步和监控:支持全量和增量数据同步,并提供详细的日志和监控功能,帮助用户快速识别和解决问题。
- 管理界面:提供直观的Web界面,用户可以轻松配置数据源、目的地和数据同步任务。
- 支持ELT模式:除了传统的ETL模式,Airbyte也支持ELT(Extract, Load, Transform)模式,允许在数据加载后在目标系统中进行数据转换。
应用场景
优势
- 社区驱动:由于是开源项目,Airbyte拥有活跃的社区支持和快速的功能更新。
- 低成本:作为开源软件,用户可以免费使用和修改,降低了数据集成的总体成本。
- 灵活性和定制性:用户可以根据自身需求开发和定制连接器和数据处理逻辑。
- 现代化架构:基于容器化的架构使得部署和扩展更加简便。
应用场景
- 数据仓库填充:从多个数据源提取数据并加载到数据仓库中,如Snowflake、BigQuery、Redshift等。
- 实时数据同步:支持实时或接近实时的数据同步,确保分析和报告基于最新的数据。
- 跨平台数据集成:在不同的应用和服务之间移动数据,以支持业务流程和分析。
Airbyte的架构
Airbyte的架构设计旨在提供一个模块化、可扩展和易于使用的数据集成平台。其架构主要由几个核心组件组成,这些组件协同工作以实现数据的提取、转换和加载。
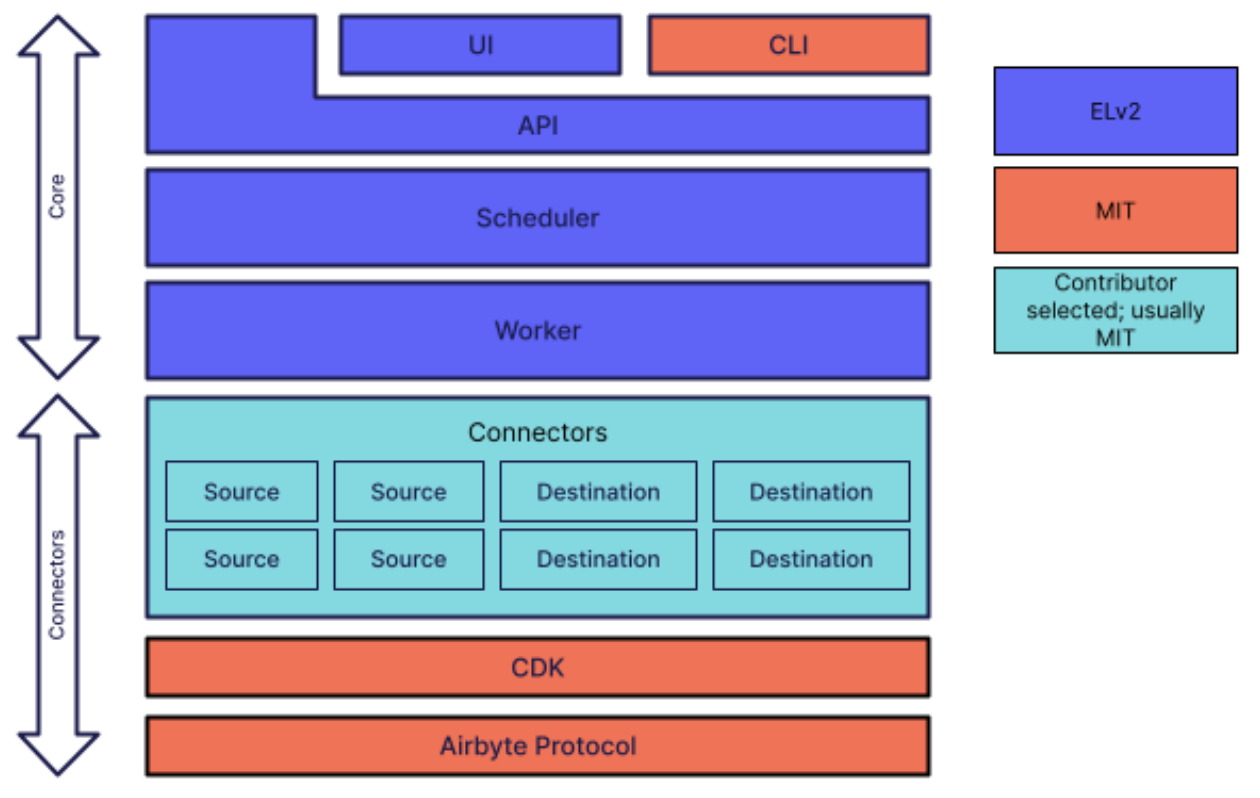
核心组件
- Connector(连接器):
- Source Connectors(源连接器):用于从各种数据源(如数据库、API、文件存储等)提取数据。
- Destination Connectors(目标连接器):用于将数据加载到目标系统(如数据仓库、数据湖、分析工具等)。
- 每个连接器都是一个独立的Docker容器,负责与特定的数据源或目标进行交互。连接器的独立性使得它们易于开发、测试和部署。
- Scheduler(调度器):
- 负责管理和调度数据同步任务。调度器确定何时运行连接器以执行数据提取和加载。
- 支持定时调度、手动触发和增量更新等多种调度策略。
- Worker(工作节点):
- 负责实际执行数据同步任务。每个任务可能涉及一个或多个连接器的协调工作。
- Worker通常在独立的计算节点上运行,以确保任务的隔离性和资源的高效利用。
- Temporal(工作流引擎):
- Airbyte使用Temporal作为其工作流引擎,用于管理复杂的任务调度和执行。
- Temporal提供了任务的容错性和重试机制,确保任务在失败时能够自动重试。
- Web Application(用户界面):
- 提供一个用户友好的界面,用于配置、管理和监控数据集成任务。
- 用户可以通过Web界面轻松创建新的连接器、配置同步任务、查看任务状态和日志。
- Database(数据库):
- Airbyte使用数据库存储配置数据、元数据和任务状态。通常使用PostgreSQL作为默认数据库。
数据流
- 配置阶段:用户通过Web界面配置源和目标连接器,包括认证信息、数据模式和同步选项。
- 数据提取:源连接器从配置的数据源提取数据。提取的数据可以是全量的,也可以是增量的。
- 数据加载:目标连接器将提取的数据加载到指定的目标系统。数据可以在加载前进行简单的转换或格式化。
- 任务监控:用户可以通过Web界面监控任务的执行状态,查看日志和错误信息。
扩展性和灵活性
- 模块化设计:Airbyte的连接器是模块化的,允许用户根据需要开发和添加新的连接器,以支持更多的数据源和目标。
- 开源社区:通过开源的方式,Airbyte社区不断贡献新的连接器和功能,提升平台的能力和适用性。
Docker 容器化:所有组件和连接器都运行在 Docker 容器中,确保了跨平台的兼容性和易于部署。
Airbyte 的架构设计使其成为一个强大且灵活的数据集成平台,能够适应现代企业多样化的数据集成需求。通过模块化和开源的方式,Airbyte 提供了一个不断演进和扩展的生态系统。
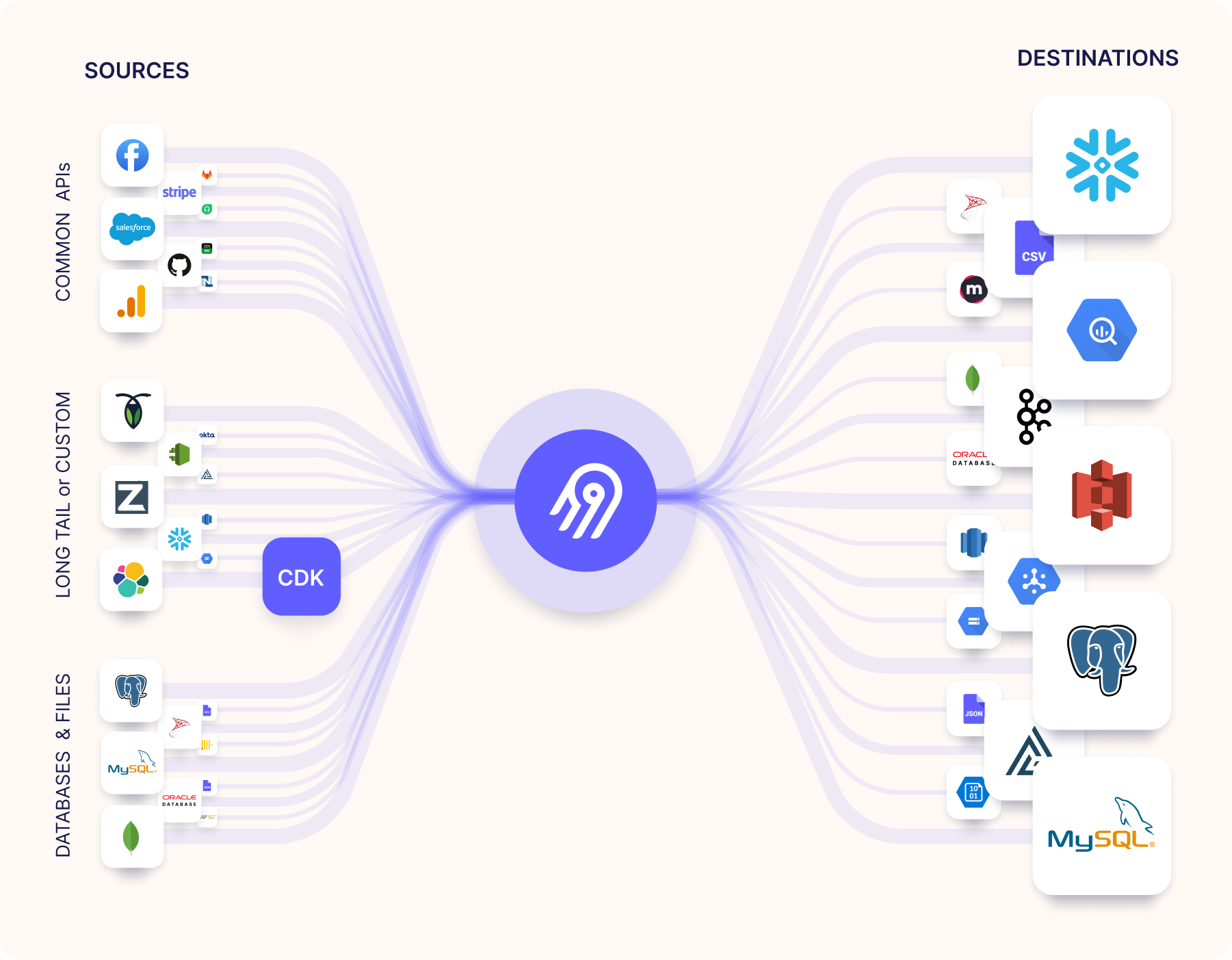
Airbyte 的连接器
Airbyte 提供了丰富的连接器库,用于支持各种数据源和数据目标。这些连接器使得用户能够轻松地将数据从不同的来源提取出来,并加载到他们所需的目标系统中。连接器通常分为两大类:源连接器(Source Connectors)和目标连接器(Destination Connectors)。以下是连接器一些常见的连接器类型:
源连接器(Source Connectors)
- 数据库:
- PostgreSQL
- MySQL
- MongoDB
- Microsoft SQL Server
- Oracle
- Amazon Redshift
- Snowflake
- 文件存储:
- CSV 文件
- JSON 文件
- Google Sheets
- 云存储和服务:
- Amazon S3
- Google Cloud Storage
- Azure Blob Storage
- API 和应用:
- Salesforce
- Stripe
- Shopify
- Google Analytics
- HubSpot
- Facebook Ads
- 流处理:
- Apache Kafka
目标连接器(Destination Connectors)
- 数据仓库和数据库:
- Amazon Redshift
- Snowflake
- Google BigQuery
- PostgreSQL
- MySQL
- Microsoft SQL Server
- 数据湖和云存储:
- Amazon S3
- Google Cloud Storage
- Azure Blob Storage
- 分析和 BI 工具:
- Google Sheets
- 流处理:
- Apache Kafka
连接器的特点
- 模块化和可扩展:Airbyte 的连接器是模块化的,每个连接器都是一个独立的 Docker 容器。这使得用户可以根据需要开发和添加新的连接器。
- 开源社区贡献:由于 Airbyte 是开源项目,社区成员可以贡献新的连接器,扩展 Airbyte 的支持范围。
- 支持增量和全量同步:许多连接器支持增量数据同步,允许用户只提取自上次同步以来的数据变化,从而提高数据同步的效率。
如何查看和使用连接器
用户可以通过 Airbyte 的 Web 界面查看可用的连接器,并选择合适的源和目标连接器来配置数据同步任务。Airbyte 的文档和社区也提供了关于如何开发自定义连接器的指南。
Airbyte 不断增加新的连接器,以满足不断变化的用户需求。为了获取最新的连接器列表和支持状态,建议访问 Airbyte 的官方网站或其 GitHub 仓库。
参考链接:


