MongoDB相对于传统的关系型数据库,可以存储JSON数据,非常适合存储数据抓取返回的JSON数据。先前介绍过MongoDB在Windows的安装,今天主要学习的是使用Python连接MongoDB,并进行增删改查的操作。 在连接MongoDB…

Implicit简介 Implicit是一个开源的协同过滤项目,其包含多种流行的推荐算法,主要应用场景是针对隐性反馈行为进行推荐。包含的算法主要有: ALS(alternating least squares),最小交替二乘法 BRP(Bayesian P…
在使用Python执行一些比较耗时的操作时,为了方便观察进度,通常使用进度条的方式来可视化呈现。Python中的tqdm就是用来实现此功能的。 先来看看tqdm的进度条效果: tqdm基本用法 tqdm最主要的用法有3种,自动…

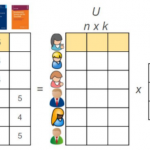
FastFM 简介 FastFM 的主要特点是将是将因子分解 封装成 scikit-learn API 接口,核心代码使用 C 编写,性能有一定的保障。 fastFM 主要提供了回归、分类、排序三种问题的解决方法。其中对于优化器,有als,mcmc…

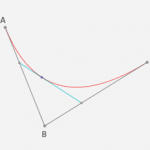
什么是贝塞尔曲线 贝塞尔曲线的数学基础是早在1912年就广为人知的伯恩斯坦多项式。但直到1959年,当时就职于雪铁龙的法国数学家Paul de Casteljau才开始对它进行图形化应用的尝试,并提出了一种数值稳定的de Castel…
Surprise简介 Surprise(Simple Python Recommendation System Engine)是一款推荐系统库,是scikit系列中的一个。surprise设计时考虑到以下目的: 让用户完美控制他们的实验。为此,特别强调文档,试图通过指出…

前面我们学习了腾讯Item-based CF实时推荐算法,这篇文章延续同样来自腾讯,介绍的是腾讯实时视频推荐系统的实践。内容来自论文: Real-time Video Recommendation Exploration 这篇论文中的内容。 简介 传统的技术…
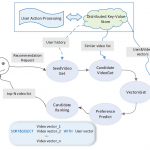
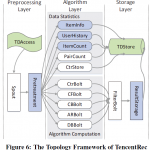
以下内容主要翻译自2015年腾讯发表的论文 TencentRec: Real-time Stream Recommendation in Practice。对于推荐的搭建还是非常有借鉴意义。 简介 传统的推荐系统通过定期(几小时或几天)分析和更新模型并不能满足…
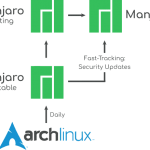
什么是Manjaro? Manjaro,简单的说它是基于Arch Linux的发行版,Manjaro的目标是让强大的Arch更方便用户使用,比如说安装流程,相比Arch Linux安装时要使用命令行进行分区、挂载分区、网卡设定等,它直接提供类似…
最近把家里的电脑重新进行了安装,一开始只安装了Manjaro,原本计划彻底放弃Windows,但是发现纯粹用Linux在某些方面效率反而会下降。于是决定安装Windows、Linux双系统。Windows和Linux双系统安装的时候还是遇到很…