在之前的文章中,分别介绍了决策树模型XGBoost和贝叶斯优化工具Optuna,在实际使用中还是会多多少少遇到一些问题。今天文章主要针对Optuna优化XGBoost做下梳理。 XGBoost的目标函数 XGBoost提供了多种内置的目标…
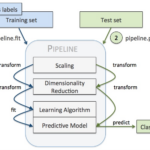
Scikit-Learn的Pipeline是一个工具,可以将多个数据预处理和建模步骤连接起来,形成一个完整的机器学习工作流。它允许用户通过链式执行多个转换步骤并最终拟合一个模型,从而使代码更加简洁。下面我们将详细介绍Pip…
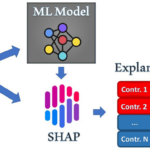
机器学习在很多领域取得了重要的进步,也帮助人减少了不少体力劳动。要训练一个机器学习模型,以及将模型应用在实际场景中,最重要的是数据的收集以及处理。那么,如何使用模型指导数据收集就成了一个重要的问题,…
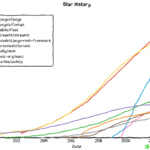
在学习Python过程中,如果学习Web开发,一般会涉及到Web框架,特别是对于新手,除了主流的Django和Flask,一般不会了解还有哪些框架更能适合自己。今天主要从Github的Star数量进行统计,将热门的开源Python Web框架…
在scikit-learn中,要对一个拟合好的模型进行评估,有三种方法: 使用各种estimator自带的score方法。一般来说,分类器的默认评估指标是正确率(accuracy),回归器的是拟合优度(R方)。 使用模型评估工具…
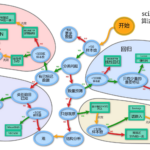
随着互联网的发展,网站的反爬虫技术也在不断提升。其中最常见的一种手段就是对IP地址进行封禁,防止爬虫程序访问网站。为了避免这种情况的发生,爬虫程序需要使用动态IP代理来隐藏自己的真实IP地址。本文将介绍Pyt…
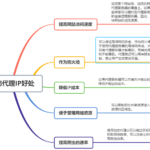
用户代理User-Agent 客户端向服务器请求一张页面时,可以额外附上一些自己的信息(如使用什么操作系统、什么浏览器),以便让服务器提供更好的服务(如根据不同设备返回不同的页面)。额外附上的信息叫请求头(HTT…

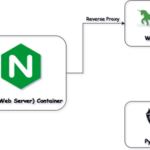
想要将Python Web应用部署到线上,目前主流的方案是在Gunicorn/uWSGI前面再加一层Nginx,其中Nginx的主要作用是: 做负载均衡,便于后期服务器的水平扩展,可轻松将应用部署到多台服务器或多个进程中。 缓…
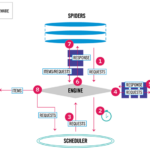
Scrapy 是一个 Python 爬虫框架,用于快速、高效地抓取网页数据。它通过异步方式处理 HTTP 请求和响应,支持多线程和分布式部署,可以方便地从互联网上获取大量的结构化数据。 使用Python来做抓取程序非常的方便…
在工作中,有时需要用到Git。对于很多开发而言,Git的使用可能非常的简单,而对于数据分析的小伙伴,可能有由于先前没有接触过,可能不太了解。今天要介绍的是Github的使用,对于很多公司内部使用自己部署的Gitlab…






