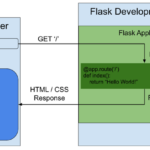
在Flask中,路由是将URL请求分配到相应的处理程序的方法。每个路由可以映射到一个特定的视图(视图函数或方法)。一个 WEB 应用不同的路径会有不同的处理函数,路由就是根据请求的 URL 找到对应处理函数的过程。在…
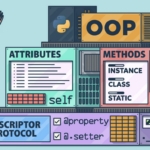
当我们谈论面向对象时,就像在搭积木一样,每个积木都是一个特殊的东西,而整个搭建起来就是一个大作品。在编程中,面向对象是一种方法,你可以把不同的东西(比如动物、车辆、游戏角色)看作是特殊的“积木”,每个“…
在先前的文章,已经很详细的介绍了LightGBM的原理及使用示例。模型的安装与调用本身不会遇到很大的问题,实际使用过程中遇到的最大难题是如何优化超参数。由于没有进行很好的超参数优化导致产生的模型性能存在欠缺…

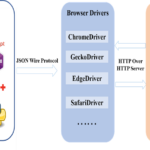
Selenium简介 Selenium是浏览器的自动化测试工具,与浏览器进行交互,实现对web应用的自动化测试,Selenium包括Selenium IDE, Selenium Webdriver 和 Selenium Grid三个工具。 Selenium IDE (Integrated Deve…
在之前的文章中,分别介绍了决策树模型XGBoost和贝叶斯优化工具Optuna,在实际使用中还是会多多少少遇到一些问题。今天文章主要针对Optuna优化XGBoost做下梳理。 XGBoost的目标函数 XGBoost提供了多种内置的目标…
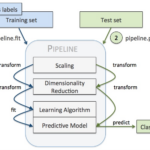
Scikit-Learn的Pipeline是一个工具,可以将多个数据预处理和建模步骤连接起来,形成一个完整的机器学习工作流。它允许用户通过链式执行多个转换步骤并最终拟合一个模型,从而使代码更加简洁。下面我们将详细介绍Pip…
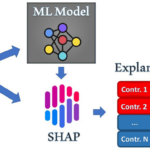
机器学习在很多领域取得了重要的进步,也帮助人减少了不少体力劳动。要训练一个机器学习模型,以及将模型应用在实际场景中,最重要的是数据的收集以及处理。那么,如何使用模型指导数据收集就成了一个重要的问题,…
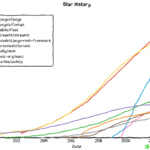
在学习Python过程中,如果学习Web开发,一般会涉及到Web框架,特别是对于新手,除了主流的Django和Flask,一般不会了解还有哪些框架更能适合自己。今天主要从Github的Star数量进行统计,将热门的开源Python Web框架…
在scikit-learn中,要对一个拟合好的模型进行评估,有三种方法: 使用各种estimator自带的score方法。一般来说,分类器的默认评估指标是正确率(accuracy),回归器的是拟合优度(R方)。 使用模型评估工具…
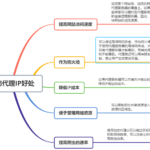
随着互联网的发展,网站的反爬虫技术也在不断提升。其中最常见的一种手段就是对IP地址进行封禁,防止爬虫程序访问网站。为了避免这种情况的发生,爬虫程序需要使用动态IP代理来隐藏自己的真实IP地址。本文将介绍Pyt…