LibShortText LibShortText是一个开源的Python短文本(包括标题、短信、问题、句子等)分类工具包。它在LibLinear的基础上针对短文本进一步优化,主要特性有: 支持多分类 直接输入文本,无需做特征向量化…
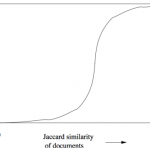
在数据挖掘中,一个最基本的问题就是比较两个集合的相似度。通常通过遍历这两个集合中的所有元素,统计这两个集合中相同元素的个数,来表示集合的相似度;这一步也可以看成特征向量间相似度的计算(欧氏距离,余弦…
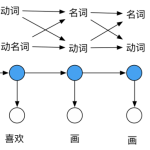
词性标注(Part-of-Speech tagging 或POS tagging),又称词类标注或者简称标注,是指为分词结果中的每个单词标注一个正确的词性的程序,也即确定每个词是名词、动词、形容词或其他词性的过程。词主要可以分为以下2…
结巴分词 就是前面说的中文分词,这里需要介绍的是一个分词效果较好,使用起来像但方便的Python模块:结巴。 结巴中文分词采用的算法 基于Trie树结构实现高效的词图扫描,生成句子中汉字所有可能成词情况…

NLTK简介 NLTK(Natural Language Toolkit)是由宾夕法尼亚大学计算机和信息科学使用python语言实现的一种自然语言工具包,其收集的大量公开数据集、模型上提供了全面、易用的接口,涵盖了分词、词性标注(Part-Of-Sp…
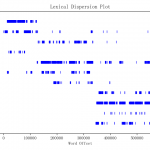
最近收到了对两个平台进行对比调研的需求,原以为做下简单的问卷设计就可以了,找了一些资料发现中间的门道还是非常的深,想要很好的掌握实属不易。可用性测试的问卷有很多中,如下图: 什么是标准化的问卷 …
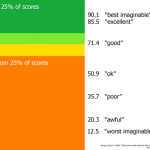
以下内容梳理自广为流传的Netflix Culture: Freedom & Responsibility,仅是摘录一些个人觉得比较有用的观点,如需了解全部,建议看原版。 价值观 真正的价值观是被员工所重视的行为和技能,是具体通过哪…

Wordcloud是一个生成词云的Python包,可以以词语为基本单位更加直观和艺术的展示文本,呈现效果类似标签云。这里主要讲解下如何使用。 wordcloud使用文档 所有函数均封装在WordCloud类里: WordCloud([...]) …

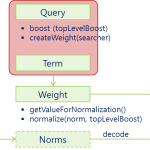
当谈论到查询的相关性,很重要的一件事就是对于给定的查询语句,如何计算文档得分。文档得分是一个用来描述查询语句和文档之间匹配程度的变量。如果你希望通过干预Lucene查询来改变查询结果的排序,你就需要对Lucen…
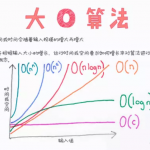
算法复杂度是算法性能最基本的评价标准。算法复杂度由时间复杂度和空间复杂度组成,属于计算复杂性理论中的内容。 时间复杂度 时间复杂度描述了算法的运行时间, 算法的时间复杂度是一个函数,它定量描述了该算法…