Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库,简单来说,它能将HTML的标签文件解析成树形结构,然后方便地获取到指定标签的对应属性。这个特性lxml差不多。 Beautiful Soup的安装 Beautif…

Requests 库是用来在Python中发出标准的HTTP请求。它将请求背后的复杂性抽象成一个漂亮,简单的API,以便你可以专注于与服务交互和在应用程序中使用数据。 Requests POST/GET 参数 常用参数见下表: Req…

数据抓取时,经常遇到由于网络问题导致的程序异常,一开始的做法只是记录了错误内容,并对错误内容再进行后期处理。这里整理了一些更好的异常重试方法或机制。 初始版本: def crawl_page(url): pass …

在数据抓取过程中,经常遇到需要解析HTML中的内容,常用的是用正则表达式,今天主要介绍lxml工具及xpath的语法。 lxml简介 lxml 是一款高性能Python XML 库,它天生支持 XPath 1.0、XSLT 1.0、定制元素类,甚至 P…
条件随机场(conditional random field, CRF)是用来标注和划分序列结构数据的概率化结构模型。言下之意,就是对于给定的输出,标识序列Y和观测序列X,条件随机场通过定义条件概率P(Y|X),而不是联合概率分布P(X, Y)…
Linux下文件的压缩与解压缩与Windows环境下有较大的区别,在Windows下只需要安装类似Winrar工具就能解压缩大部分文件,而在Linux命令行下每一种文件都有不同的压缩和解压缩方法。 常用Linux压缩解压缩命令 使…

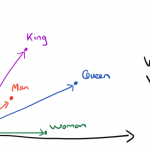
随着 NLP 的发展,像 Word2Vec、Glove 这样的词向量模型,正逐渐地被基于 Transformer 的 BERT 等模型代替,不过经典始终是经典,词向量模型依然在不少场景发光发热,并且仍有不少值得我们去研究的地方。本文来关心…
中文繁体、简体的差异,在NPL中类似英文中的大小写,但又比大小写更为复杂,比如同样为繁体字,大陆、香港和台湾又不一样。 OpenCC(Open Chinese Convert) OpenCC是一个开源的中文繁简转化项目,支持词汇级…

在计算机科学中,字符串模糊匹配(fuzzy string matching)是一种近似地(而不是精确地)查找与模式匹配的字符串的技术。换句话说,字符串模糊匹配是一种搜索,即使用户拼错单词或只输入部分单词进行搜索,也能够找…
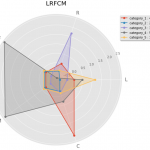
谈到用户分类模型,最被谈及的应该就是RFM模型了。大部分人常把RFM模型挂在嘴边,而在实际使用中的却很难真正的利用起来。这里暂时不去讨论RFM是好是坏。今天的介绍的是另外一个拓展的模型:航空公司客户价值分析模…