Pregel简介
Pregel是由 Google 提出的一个专门用于大规模图计算 的分布式系统框架,旨在高效处理超大规模图数据,如社交网络、Web 图、道路网络等。Pregel 的设计受 Google MapReduce 成功经验的启发,但针对图计算场景优化,解决了如图遍历、最短路径、图划分等问题。
产生背景
Google Pregel 的产生背景与大规模图数据的处理需求密切相关。在 21 世纪初,随着互联网的迅速发展,许多应用生成了庞大的图数据集,例如社交网络、网络结构、推荐系统和生物信息学中的基因网络等。这些图数据通常具有以下特征:
- 规模庞大:图的规模可能包含数十亿个顶点和数千亿条边,这远远超出了单机系统的处理能力。
- 复杂的图计算:许多算法需要在图上进行复杂的计算,例如 PageRank、最短路径、社区检测等。这些算法通常需要迭代地处理图结构,并涉及大量的顶点和边。
- 分布式处理需求:由于单台机器无法有效处理如此大规模的数据,必须采用分布式系统将计算任务分布到多个节点上。
- 容错性和可扩展性:处理如此庞大的数据集要求系统具有良好的容错能力和可扩展性,以应对节点故障和动态负载变化。
在这种背景下,传统的图处理方法显得力不从心。Google 的工程师们认识到,需要一种新的计算模型来有效处理大规模图数据。于是,Google Pregel 应运而生,旨在为大规模图处理提供一个高效、可扩展且容错的分布式计算框架。
Pregel 的设计灵感来自 Bulk Synchronous Parallel (BSP) 模型,这是一种常用于并行计算的模型。BSP 模型强调同步的超级步计算和消息传递机制,这与图计算中的迭代过程和顶点间通信需求相匹配。通过将图的计算过程划分为多个超级步,Pregel 能够在分布式环境中高效地进行图计算,同时提供简单的编程接口,使开发者能够专注于顶点的计算逻辑,而无需关心底层的并行化和通信细节。
总之,Google Pregel 的产生是为了应对大规模图数据处理的挑战,为互联网时代的各种复杂应用提供了一种强有力的解决方案。其设计思想不仅解决了当时的实际问题,也对后来的分布式图处理框架产生了深远影响。
核心特性
Google Pregel 是一种专门为大规模图处理设计的分布式计算框架,其核心特性主要包括以下几个方面:
- 以顶点为中心的计算模型:Pregel 采用以顶点为中心的编程模型,每个顶点是一个计算单元。开发者只需定义顶点的计算逻辑,框架会负责将这些计算分布到多个节点上执行。
- 超级步(Superstep)机制:Pregel 的计算过程分为一系列的超级步。在每个超级步中,顶点接收来自其他顶点的消息,进行计算,更新自身状态,并向其他顶点发送消息。所有顶点在一个超级步内的计算是并行的。
- 消息传递:顶点之间通过消息传递进行通信。每个顶点可以在一个超级步中接收来自其他顶点的消息,并在计算后向其他顶点发送消息。
- 同步机制:Pregel 使用同步的超级步来协调计算。每个超级步结束时,所有顶点都必须完成当前计算,才能进入下一个超级步。这种同步机制有助于确保计算的一致性。
- 容错性:Pregel 支持检查点机制,以应对节点故障。系统会定期保存计算状态的快照(检查点),在发生故障时可以从最近的检查点恢复,从而保证计算的容错性。
- 可扩展性:Pregel 设计用于处理大规模图数据,可以通过增加计算节点来扩展计算能力。其分布式架构能够有效地利用集群资源进行大规模并行计算。
- 终止条件:计算过程可以在所有顶点都进入停用状态且没有消息在系统中传递时终止。顶点可以根据自身状态和接收到的消息决定是否停用。
- 简化的编程接口:Pregel 提供了一种简单的编程接口,开发者只需专注于实现顶点的计算逻辑,无需关心底层的分布式处理和通信细节。
通过这些核心特性,Google Pregel 提供了一种强大而灵活的框架,适合处理各种大规模图计算任务。它的设计理念对后续的图处理系统(如 Apache Giraph 和 Apache Hama)也产生了重要影响。
应用场景
优点
- 高效分布式计算:Pregel 通过分区和并行计算,能够处理 TB 甚至 PB 级别的图数据。
- 简化编程:把图计算抽象成顶点行为,开发者只需关注局部逻辑。
- 负载均衡:通过合理的图分区策略,减少分布式系统的通信开销。
- 容错能力:支持自动恢复,保证长时间运行任务的可靠性。
局限性
- 同步模型开销:BSP 模型需要同步所有节点,可能导致全局瓶颈。
- 通信成本高:如果图划分不合理,会导致大量跨分区通信。
- 学习曲线:用户需要熟悉分布式计算和图计算模型。
应用场景
- 社交网络分析:用户关系图、影响力传播、社区发现等。
- 搜索引擎优化:PageRank、链接分析等。
- 推荐系统:用户与物品的双向图关系建模。
- 地理信息系统(GIS):路径规划、网络优化等。
- 生物信息学:基因网络分析、蛋白质交互图等。
与其他框架的比较
| 特性 | Pregel | Apache Giraph | GraphX (Spark) | Neo4j |
| 模型 | BSP | BSP | RDD + Pregel | 面向查询 |
| 存储类型 | 内存 + 分布式 | 内存 + 分布式 | 内存 + 分布式 | 磁盘 + 索引 |
| 性能 | 高效(特定任务) | 高效(优化后) | 通用但稍逊 | 查询优化 |
| 容错 | 检查点机制 | 检查点机制 | RDD 容错 | 不支持 |
| 编程接口 | Java | Java | Scala/Java/Python | Cypher 查询语言 |
Pregel 的实现与扩展
- Google Pregel:Pregel 是 Google 内部实现,未开源,但理念影响深远。
- Apache Giraph
- 基于 Pregel 的开源实现,运行于 Hadoop。
- Apache Spark GraphX:在 Spark 框架上实现 Pregel 算法,利用 Spark 的 RDD 特性。
- 其他实现:Apache Hama
Pregel 的实现逻辑
核心思想
Pregel 基于一种被称为BSP(Bulk Synchronous Parallel) 的并行计算模型。图的每个顶点被视为一个独立的计算单元,顶点通过消息传递与相邻顶点通信,从而完成整个图的计算。
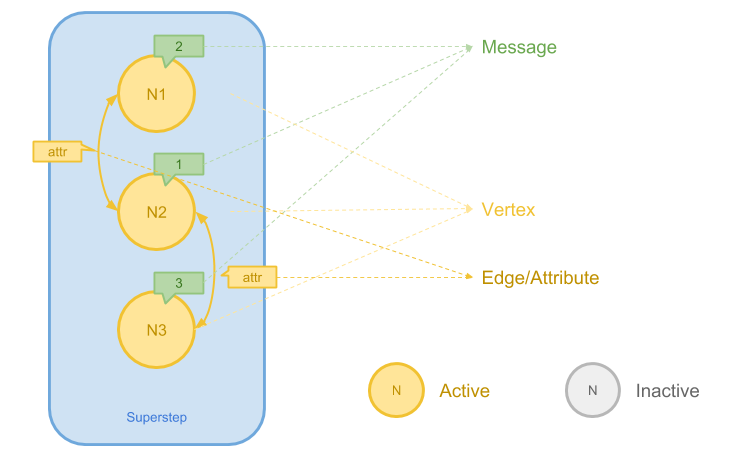
- 顶点为核心:
- 图中的每个顶点是计算的基本单位,具有自己的状态(如值、标签)。
- 顶点可以向邻居发送消息,接收消息,并根据消息更新状态。
- 超级步(Superstep):
- Pregel 的计算由一系列同步的超级步组成。
- 每个超级步分为以下步骤:
- 顶点处理接收到的消息。
- 更新顶点的状态。
- 向相邻顶点发送消息。
- 所有顶点的计算在超级步内完成后,才会进入下一个超级步。
- 消息传递:
- 顶点通过边向其他顶点发送消息,消息在超级步之间传递。
- 计算终止:
- 每个顶点可以在特定条件下投票退出计算(即“停用”状态)。
- 当所有顶点都停用且没有消息传递时,计算结束。
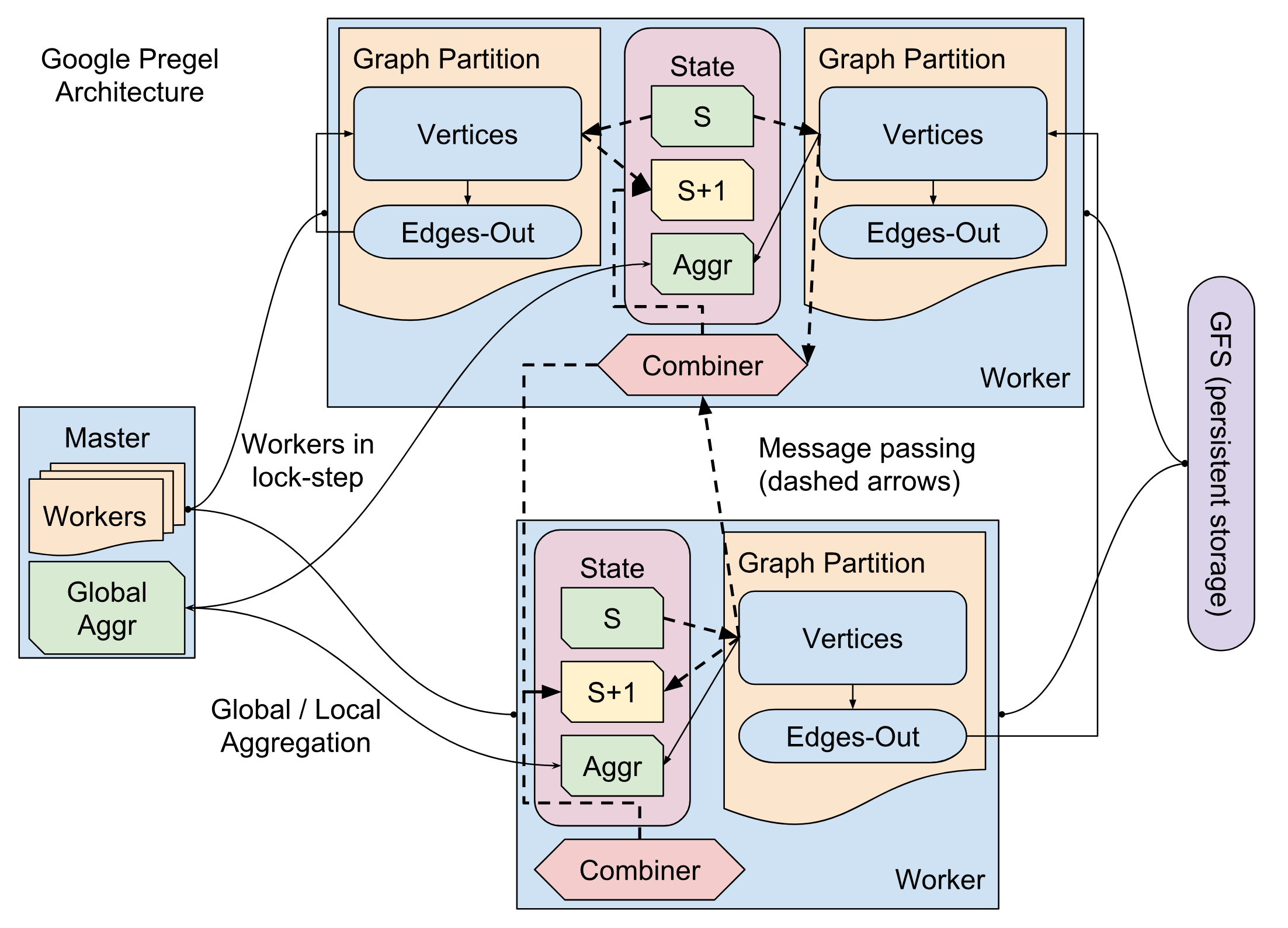
体系结构
Pregel 是一个主从结构 的分布式框架:
- 主控节点(Master):
- 负责分配任务、协调超级步同步。
- 管理全局状态,如图的分区、故障恢复等。
- 工作节点(Workers):
- 分布式地处理图的分区。
- 每个工作节点负责一部分顶点及其边。
- 分区策略:
- Pregel 将图划分为多个分区,尽量减少跨分区通信。
- 通常按顶点 ID 或其他自定义策略划分。
编程模型
Pregel 的编程接口主要包含以下几个部分:
- 顶点类(Vertex Class):
- 每个顶点继承自一个抽象类。
- 实现用户定义的 compute() 函数,该函数定义了顶点在每个超级步中的行为。
- 消息传递:
- 使用 sendMessageTo() 方法向特定顶点发送消息。
- 消息在下一个超级步中由目标顶点接收。
- 超步控制:
- 顶点可以调用 voteToHalt() 来暂停自己的计算。
- 当顶点再次接收到消息时,会重新激活。
参考链接: